●32個のRAMに書いて次の層に渡す
図8-89のようにtb_conv_hw/conv_hw_1の下にはRAM_Z3_00〜31まで32個のRAMがあり、それぞれに出力チャネルの画像データが書かれています。これらが3層目の結果であり、4層目の入力になります。 |
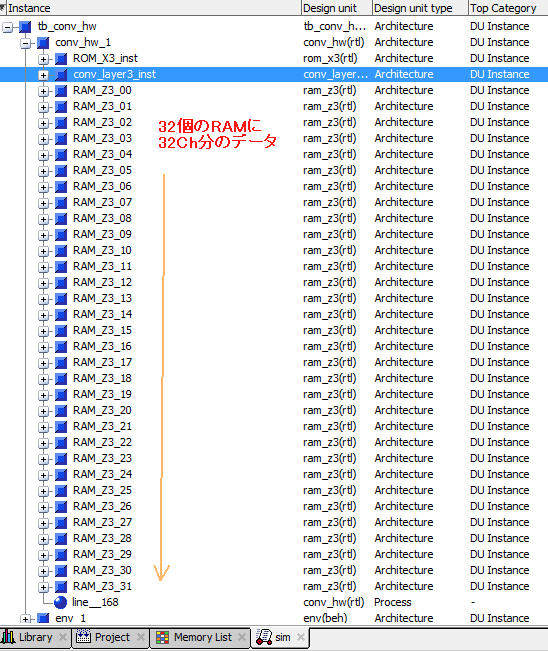
図8-89 ModelSimのSimタブ
●8枚づつ4回に分けて順次計算
画像32枚は8枚づつ、4回に分けて演算されます。図8-90のように約18usのシーケンスを4回行い、合計72us程度で終了します。 |
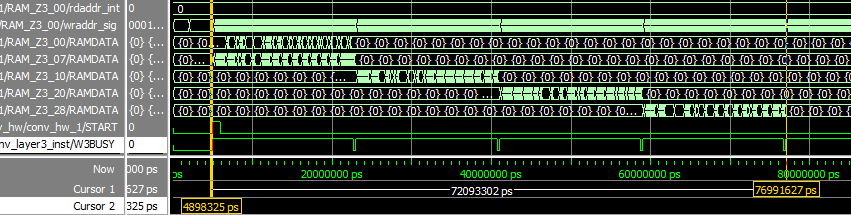
図8-90 RAM_Z3_07、RAM_Z3_10、RAM_Z3_20、RAM_Z3_28、それぞれ書き込まれるタイミングが違う
●1、2、3層ほぼ同じサイクル数で処理させる
第6章で畳み込み1層目、第7章で2層目、本章では3層目をVHDL化しました。各層のサイクル数と時間をと比較したものを表8-01に示します。 |
表8-01 各層にかかる時間(MNIST画像1枚あたり、1サイクル = 10ns)
|
畳み込み1層目 |
畳み込み2層目 |
畳み込み3層目 |
| サイクル数 |
7.1k |
7.1k |
7.2k |
| 時間 |
71us |
71us |
72us |
| 乗算器 |
16個 |
256個(ビットシフト算型) |
128個(ビットシフト型) |
| 将来的にパイプライン化することを考えると表8-01のように1、2、3層ほぼ同じサイクル数で処理させることが大事です(その理由はここ)。3層目だけ必要以上に早く終わらせてもリソース(乗算器など)の無駄遣いになるだけなので注意しましょう。 |
最初のページへ
目次へ戻る |