1-06 学習から推論まで、Pythonコードの流れ
GTSRB - CNN (98% Test Accuracy、図1‐11の上のサイト)のPythonコードを簡単に説明します(*1)
(*1)不正確な部分もあるかもしれませんがご容赦ください。
●Importing Required Libraries
Tensorflow(*2)とKeras(*3)のライブラリの読み込み。
(*2)機械学習の実装パッケージ(フレームワーク)。Pytorch、Chainerなどが対抗馬(?)
(*3)ニューラルネットワークのライブラリ。Tensorflow上で動くようだ。 |
●Assigning Path for Dataset
画像のパスなどを指定。
リサイズは30x30。色々なサイズの画像を30x30画素に変換してから学習、推論
チャネル数は3。カラー画像を扱う。RGBの3色。
●Finding Total Classes
ラベルの番号と名前の関連付け。Trainフォルダにあるサブフォルダの番号と名前("0"なら"Speed limit (20km/h)"など)の関連付け(図1‐54参照) |
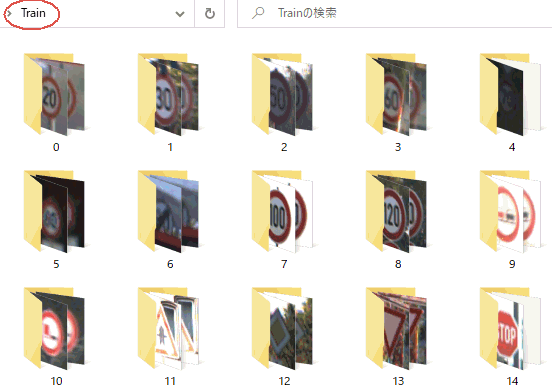
図1-54 Trainフォルダ以下に0〜42のフォルダ。43種の標識がクラス分けしてある
●Visualizing The Dataset
各ラベルに属する画像数をグラフ化
画像をランダムに25枚表示
●Collecting the Training Data
image_data.shape (39209, 30, 30, 3) この中にTrain以下の画像が39209枚入る
image_data_labels.shape (39209,) この中にTrain以下の画像のラベルが39209個入る
●Shuffling the training data
画像とラベルをランダムに並べ替え。そのおかげで学習するたびに認識率が微妙に変わってくる |
●Splitting the data into train and validation set
Trainフォルダ内の画像を訓練と検証用に分ける(*4)
X_train.shape (27446, 30, 30, 3) 訓練用画像
X_valid.shape (11763, 30, 30, 3) 検証用画像
y_train.shape (27446,) 訓練用ラベル
y_valid.shape (11763,) 検証用ラベル
(*4)訓練と検証を繰り返し、リファインしながら学習モデルを生成。その後推論する(推論用画像はまた別にある。Testフォルダ内)
●One hot encoding the labels
ラベルをOne-hot表記にする。
y_train = keras.utils.to_categorical(y_train, 10)
例えば「整数 1」を「0,1,0,0,0,0,0,0,0,0」と表現。「整数 5」を「0,0,0,0,0,1,0,0,0,0」
このようにすると各ラベルの統計がとりやすい |
●Making the model
CNNのモデルを作る(ここ参照)。CNNの形状を決める。
最適化法はAdam。モーメンタム+RMSPropという手法のようです(*6)。
コンパイルする。トレーニング方法の決定。トレーニングにおけるズレの指標となる損失関数、正解に近づける修正方法などの決定
(*6)Jupyter Labの古いバージョンならこれ opt = Adam(lr=lr, decay=lr / (epochs * 0.5)) 新しいバージョンならこれ opt = tf.keras.optimizers.legacy.Adam(lr=lr, decay=lr / (epochs
* 0.5))
●Augmenting the data and training the model
X_train.shape (27446, 30, 30, 3) 訓練用画像
X_valid.shape (11763, 30, 30, 3) 検証用画像
y_train.shape (27446,) 訓練用ラベル
y_valid.shape (11763,) 検証用ラベル
これらをFit関数に入力
画像を少し変えて水増しする。rotate shift zoomなど。batch_size=32倍?
訓練と検証を繰り返しながら学習モデル生成(図1‐55) |

図1-55 Fit関数で学習中。Epochが30に行くまでリファインしながら学習させる
●Evaluating the model
loss, accuracy, val_loss, val_accuracyのグラフを書く
●Loading the test data and running the predictions
Test.csvにテストデータの場所とクラス。Test/00001.png、ClassID=16など
テスト画像を順番に読んでリサイズ。
x_test.shape : (12630, 30, 30, 3) x_testの中に推論用テスト画像12630枚
predict関数にx_testを入れると12630個の推論結果が出る。それぞれ43個のラベル値を持つ
predict_classes関数なら最大の値のラベルだけ12630個
accuracy_score関数で正解率を得る(図1-56)
|
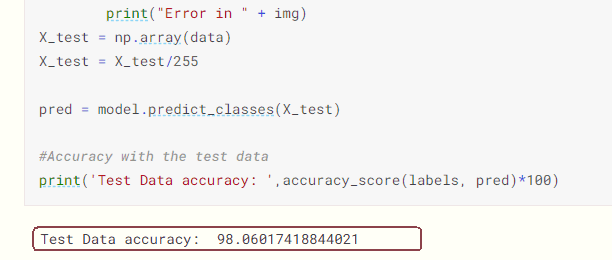
図1-56 predict_classes関数で推論を行う
●Visualizing the confusion matrix
テスト画像の推論ラベルの数を表示
●Classification report
正解ラベル列と予測ラベル列をclassification_reportに入力すると、適合率(precision)、再現率(recall)、F1スコア、正解率(accuracy)などが得られる。
●Predictions on Test Data
25枚の画像とその正解と予測ラベルを表示(*5)
(*5)赤(R)と青(B)が入れ替わっており、色がおかしいので注意 |
次のページへ
目次へ戻る
|