3-01 1層目の行列演算を並列化する
第2章ではディープラーニングの処理をVHDL化しましたが、その演算速度は速くはありません。特に
1層目
の行列でかかるサイクル数が多いので(40kサイクル、
ここ
参照)、その部分を「
並列化
」して高速化します。
●FPGAの逐次処理的使い方(前章)
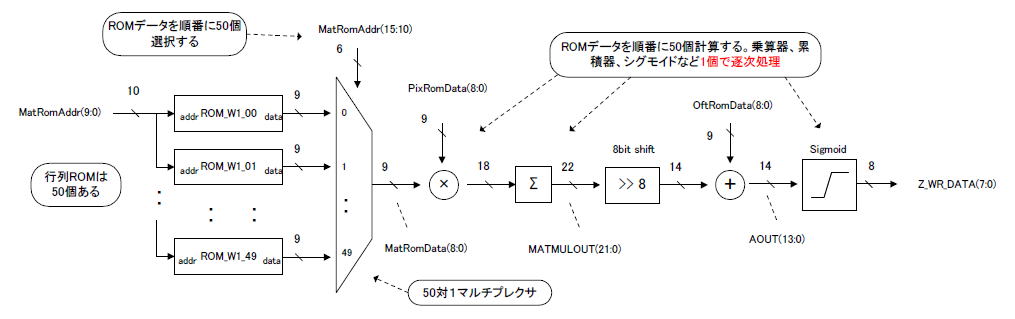
図3-01は1層目のの行列演算の部分です。行列ROMは50個あり、それらのデータは50対1のマルチプレクサに入力されます。
それ以降、乗算器、累積器、シグモイドなどの回路がありますが、それらは
1個
づつしかありません。
したがって最初にROM_W1_00をマルチプレクサで選択して演算、次はROM_W1_01、その次はROM_W1_02、・・・最後にROM_W1_49を選択して演算し、行列演算が終了します。
図3-01 前章のやり方では計算に時間がかかる
●FPGAの並列処理的使い方(
本章
)
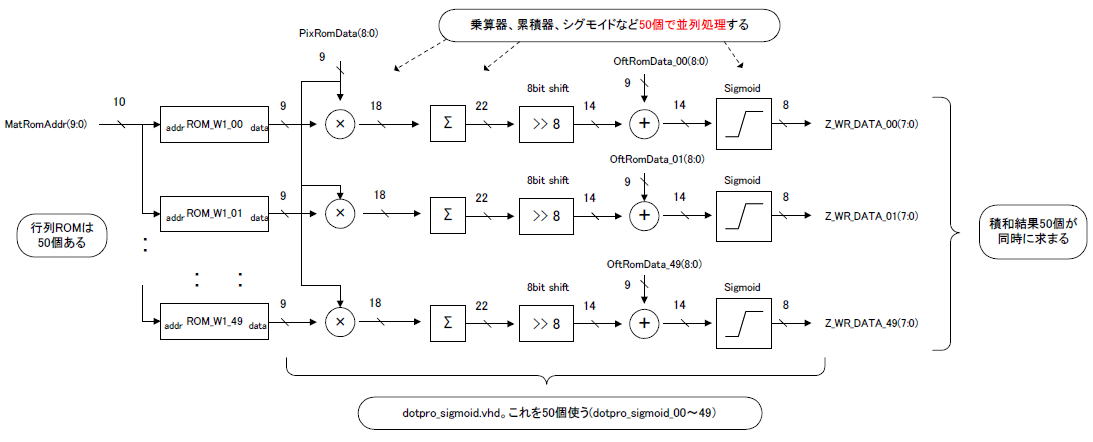
図3-02では50個のROMデータがそれぞれ直に乗算器に入力されます。乗算器、累積器、シグモイドなどの回路がそれぞれ
50個
あり、同時に動作します。
このような作業を
並列化
といい、これにより演算速度は約50倍になります。
図3-02 本章では50並列でスピードアップする
● リソースが許す限り並列化できるFPGA
FPGAは図3-01のような逐次処理的使い方や、図3-02のような並列処理的使い方を自由に選択できます。ゆっくり計算すればよい場合は前者、急いで計算するときは後者になります。表3-01にそれらのメリット、デメリットを示します。
表3-01
メリット
とデメリット
逐次処理(図3-01)
並列処理(図3-02)
FPGAのリソース
少なくて済む(乗算器1個など)
たくさん必要(乗算器50個など)
演算にかかるサイクル
多サイクルかかる
少サイクルで済む
本企画では比較的リソースの豊富なFPGAを使用することを想定して後者を選択します。「次のページ」をクリックしましょう。
次のページへ
目次へ戻る