9-03丂Affine侾丆俀憌栚偺峴楍忔嶼
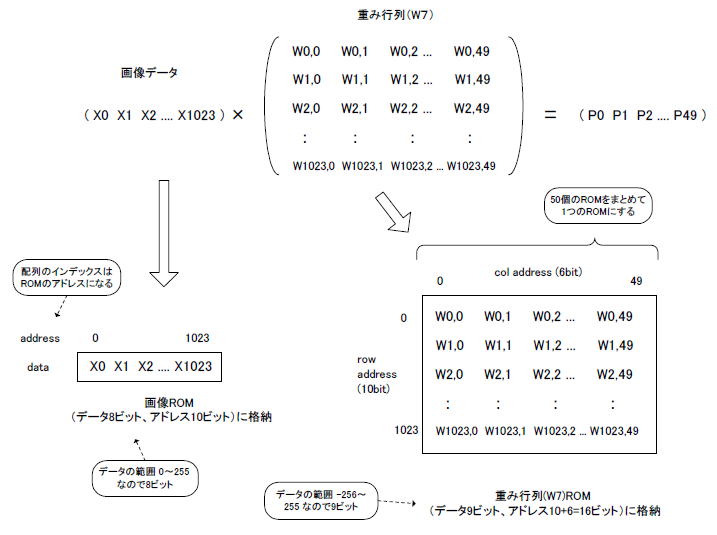 丂恾9-15丂Affine1憌栚偼擖椡偑1亊1024偱廳傒學悢偑1024亊50
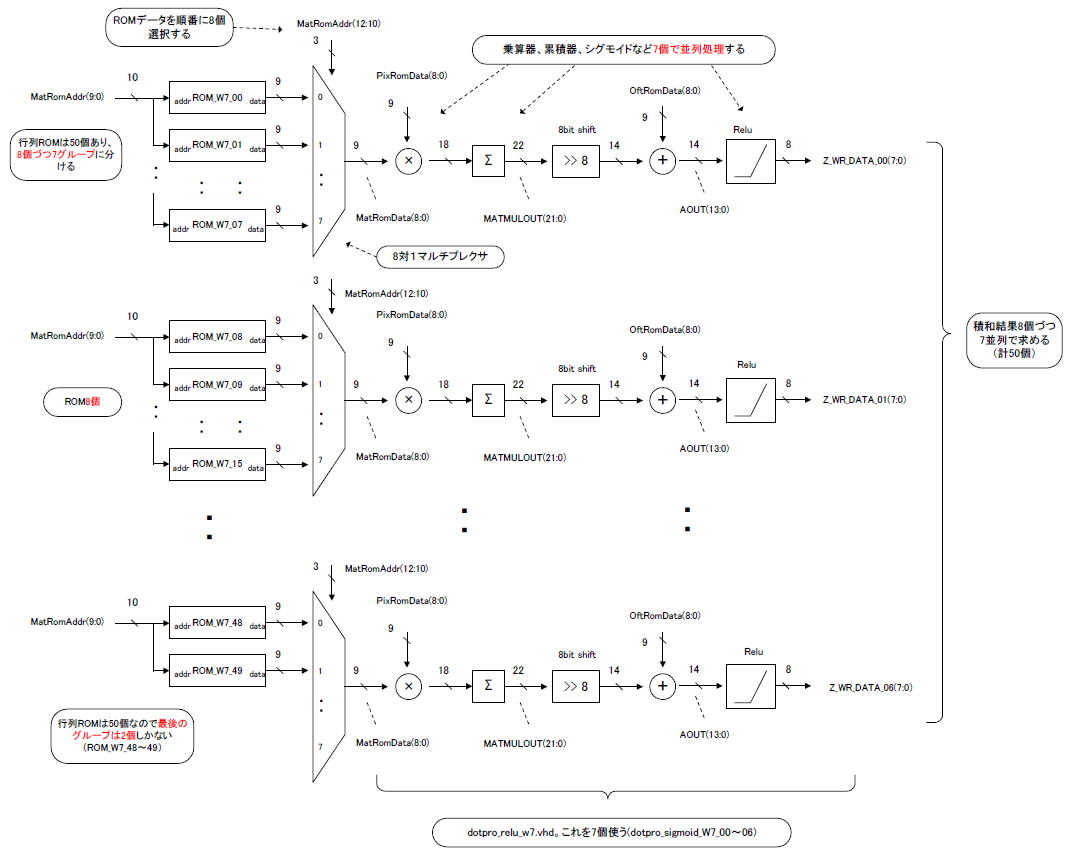 丂恾9-16丂忔嶼婍7屄丄7暲楍偱崅懍壔
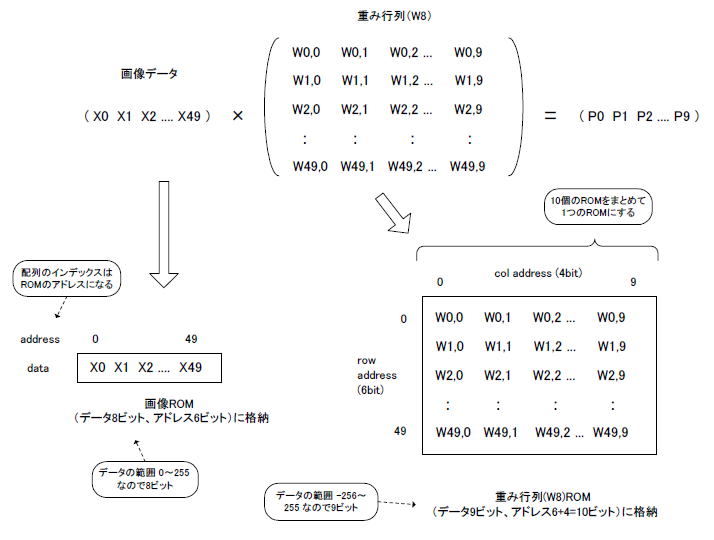 丂恾9-17丂Affine俀憌栚偼擖椡偑1亊50偱廳傒學悢偑50亊10
栚師傊栠傞 |
||||||||||||||||||||||||
9-03丂Affine侾丆俀憌栚偺峴楍忔嶼
丂恾9-15丂Affine1憌栚偼擖椡偑1亊1024偱廳傒學悢偑1024亊50
丂恾9-16丂忔嶼婍7屄丄7暲楍偱崅懍壔
丂恾9-17丂Affine俀憌栚偼擖椡偑1亊50偱廳傒學悢偑50亊10
栚師傊栠傞 |
||||||||||||||||||||||||