10-01 非パイプラインで全層繋ぐ(層レベルでは逐次処理)
●まずは非パイプラインで全層繋いで見る
前章では畳み込みニューラルネットワークを各層ごとにシミュレーションしていました。本章では図10-01のように、ひとまず「非パイプライン」で全層繋いでシミュレーションしてみます。 |

図10-01 非パイプライン接続のブロック図
●逐次処理なので遅くなる
上図のように各層は前の層が終了したのを合図に開始します。したがってスループット(MNIST画像1枚の判定結果が出てくる周期)は全層を足し合わせた時間592us(クロック周期10ns)+αになります。 |
●非パイプライン全層接続の論理シミュレーション
このアーカイブは非パイプライン全層接続のModelSim(使い方はここ)プロジェクトです。600usほど走らせるとMNIST画像の最初の1枚(数字の’7’)の判定結果が出てきます。
図10-02は各層のWxBUSY_N信号で、x層の処理が終了するとHになり、それを合図にx+1層の処理が開始されます。若干のオーバヘッド(+α)があり、全層で601usほどかかっています。 |

図10-02 600usほど走らせると全層終了する(私のマシンではシミュレーションに10時間ほどかかった)
●各層の結果を確認
図10-03は各層の間にあるRAMDATAです。RAM_Z1_NNには畳み込み1層目の出力チャネルNN画像が入っています。RAM_Z2_NNは畳み込み2層目、RAM_Z3_NNは畳み込み3層目、・・・RAM_Z7_NNはAffine1層目の出力チャネルNN画像が入っています。
各層の結果をEXCEL表と比較し、ピタリ一致していることを確認します。 |

図10-03 各層の結果が入るRAMDATAを見る
●MNIST画像の最初の1枚は数字の’7’
図10-04は判定回路(judge.vhd)の信号です。AINはAffine2層目の結果であり、EXCELとピタリ一致しています。ANSWERも’7’であり、正解であることが分かります。 |
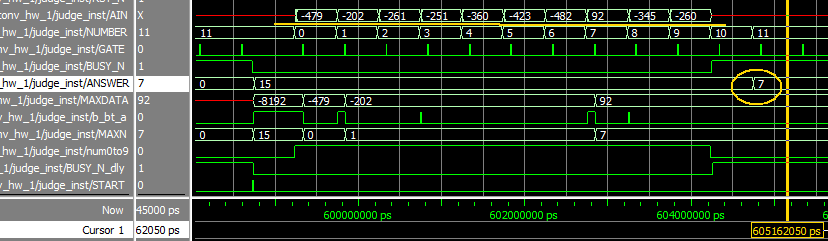
図10-04 judge_instの下にある信号たち
●非パイプラインだとスループットは600us余り
図10-01に示すように各層は同時に動くわけではなく、1層づつ順番に動きます。このように「非パイプライン」で繋ぐと処理は遅くなり、ハードウエア化の効果はあまりなくなります。
次節では「パイプライン」で繋いで高速化します。 |
目次へ戻る |