11-04 複数の小さいRAMをまとめてM10Kを効率よく使う(14章から適用)
本企画ではこのように各層の出力をRAMに格納して次段の入力とします。Cyclone Vの場合、M10KというブロックがRAMとしてアサインされます。
M10Kは約10kビットの容量を持つRAMブロックであり、そのアドレスとビット数は表11-25の組み合わせのいずれかで使用されます。 |
表11-25 M10Kのアドレスとビット数の組み合わせ
| ① |
256×32ビット(または40ビット) |
| ② |
512×16ビット(または20ビット) |
| ③ |
1024×8ビット(または10ビット) |
| ④ |
2048×4ビット(または5ビット) |
| ⑤ |
4096×2ビット |
| ⑥ |
8192×1ビット |
●今のままではM10Kを使い切ってしまう
DE1-SoC搭載のFPGA(5CSEMA5F31C6)にはM10Kがたくさんありますが(*1)、本企画のように大量の重み係数や演算結果、途中経過を格納するには注意が必要です。特に畳み込み5層目の出力はこのように64チャネル、6層目の出力もこのように64チャネルあるため、M10Kを効率よく使用するための工夫が必要になります。
(*1)Total block memoryが4Mビットなので4M/10k = 400個程度のM10Kがある?
●畳み込み5層目の出力用RAMは128個も必要
5層目の出力は8×8=64画素、各画素4ビットなのでRAMは64×4ビット、出力チャネルが64個、さらにピンポンモードで使うことを鑑みると64×4ビットのRAMが128個必要になります(図11‐31)。
この状態で論理合成→マッピングすると表11-25の④のモードでM10Kが使われ(*2)、その数は128個になってしまいます。
(*2)アドレス2048のうち64しか使用されず、極めて効率が悪い。 |
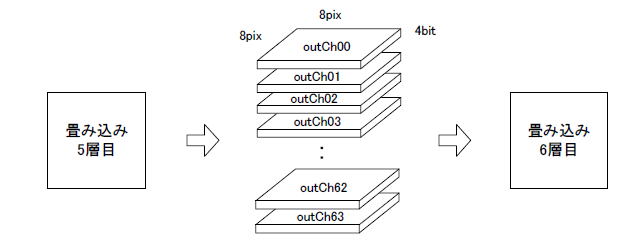
図11‐31 64×4ビットのRAMが64x2=128個
●RAMを4つ重ねるイメージ
そこで図11‐32のように4つのRAMを1つにまとめます。アドレスはそのまま、ビット数が4倍の16になるので64×16ビットのRAMとなります。こうすれば表11-25の②のモードでM10Kが使われ、その数は1/4の32個で済みます。 |
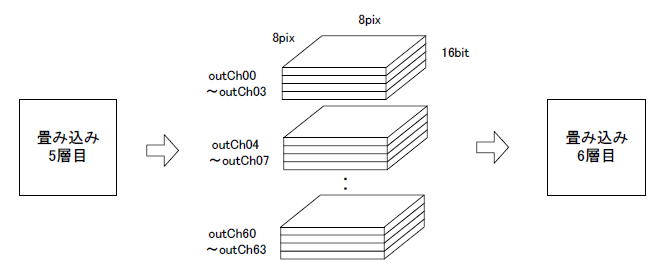
図11-32 64×16ビットのRAMが16x2=32個
●こう記述すれば効率よくマッピングされる
リスト11-31にVHDLコーディングの一部を示します。アドレスはそのまま、データは書き込みの際16ビットに結合、読み出しの際4ビット×4に分割します。 |
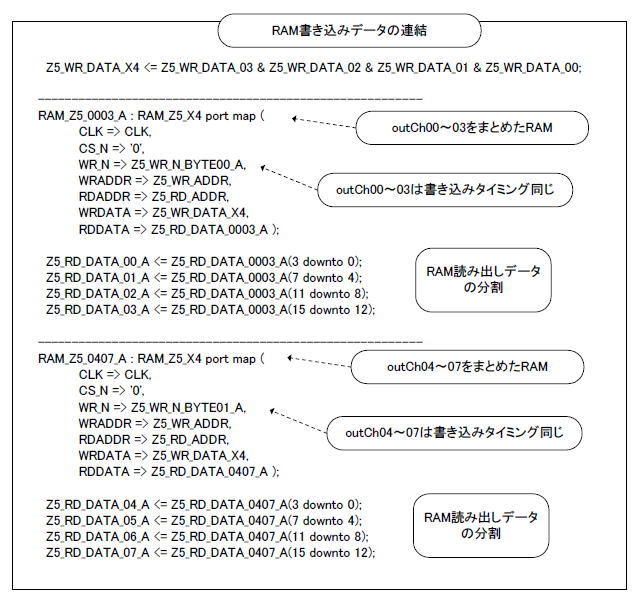
リスト11-31 書き込みデータを結合して読み出しデータを分解する
●6層目も同様にしてM10Kを128個→32個に!
また、6層目の出力は4×4=16画素、各画素4ビットなのでRAMは16×4ビット、出力チャネルが64個、ピンポンモードを鑑みると16×4ビットのRAMが128個必要になります。
6層目も同様に4つのRAMを1つにまとめると、M10Kの数は1/4の32個で済みます。以上により、5層目と6層目で計200個近くのM10Kを節約することができます。(*3)
(*3)このM10K削減手法は第14章から適用されます。 |
目次へ戻る |