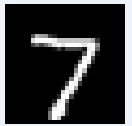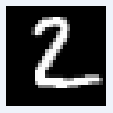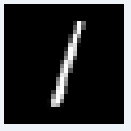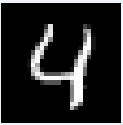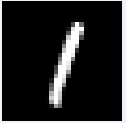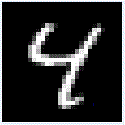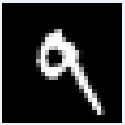●6層目が一番遅いのでそのタイミングで各層開始
前節では畳み込み1〜6層目、Affine1〜2層目を「非パイプライン」で繋ぎました。本節ではそれを「パイプライン化」してさらなる高速化を図ります。図10-10にそのブロック図を示します。6層目が終わるタイミングですべての層が作業を始めます。 |

図10-10 パイプライン接続のブロック図
●書き込みと読み出しを同時に行うための工夫
全層並列に動作させるためには上図のRAM_Z1〜RAM_Z7は、書き込みと読み出しを同時に行う必要があります。したがって読み出し中にデータが上書きされないような工夫が必要になります。
そこでRAM_Z1の内部に図10−11のように2個のRAMを設け、それらを「ピンポンモード」で使用します。W6BUSY_N(6層目が開始でL、終了でHになる信号)の立ち上がりでトグルするODD信号を生成し、それでセレクタを切り替えます。同図のような使い方をすれば読み出し中にデータが上書きされることはありません。 |
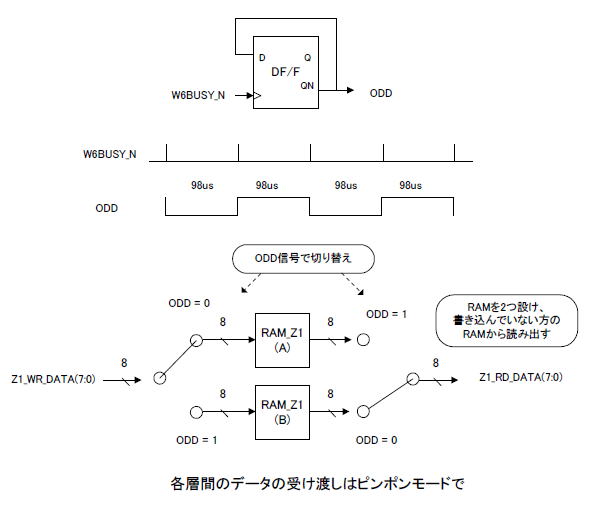
図10-11 書いている最中に読まない工夫はピンポンモードで
●パイプライン全層接続の論理シミュレーション
このアーカイブは非パイプライン全層接続のModelSim(使い方はここ)プロジェクトです。
図10-12にMNIST画像の最初の8枚の画像を示します。これらの画素データはROM_X.vhd(図10-10の最初の画像ROM)から100us毎に出力され、畳み込み1〜6層目、Affine1〜2層目を通って判定されます。 |
図10-12 MNIST画像の最初の8枚
●画像が8枚出てくる。それらの判定結果を確認
図10-13はシミュレーションを1500usほど流した結果です。同図のANSWER信号がそれで、正しく判定されていることが分かります。パイプライン化されているので判定結果は100us毎に出てきます。これがスループットになります(*1)。
(*1)図10-10では6層目の作業時間が98usだが、多少の余裕を持たせて100usで走らせることにした。
また同図では1枚目の判定結果’7’が出てくるのに700usほどかかっています。これがレイテンシになります。 |
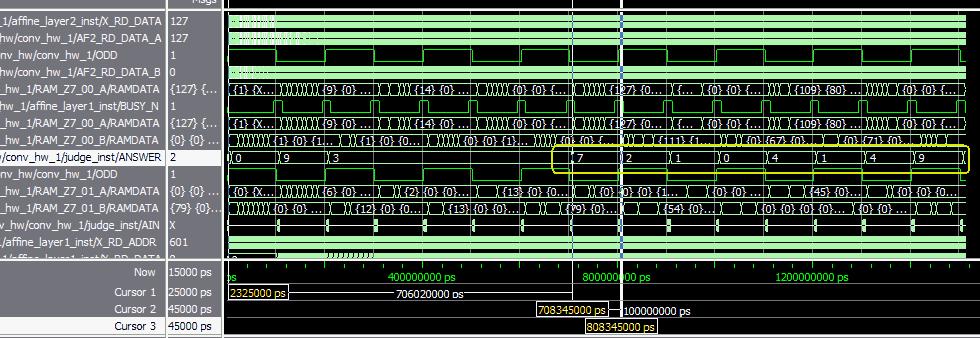
図10-13 8画像の判定結果は皆正解!(ANSWER信号)
次のページへ
目次へ戻る |