2-05 ステップ2:推論用画像セットで認識率を確認
ロードマップ(図2-10)に戻って確認しましょう。「学習用画像セット」を使って学習を行い、「学習済みモデル」を作成したところです。それを「推論用画像セット」に適用します。
●推論用画像(数百枚)は学習用画像(数千枚)よりも少なめ
train_1.zipは「学習用」の画像でしたが、「推論用」も必要です。val_1.zip(作成法はここ)をノートブックにアップロードして解凍します(!unzip val_1.zip, 図2‐21)。 |
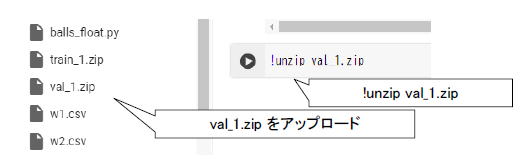
図2‐21 推論に使う画像セットを解凍する
| val_1フォルダ以下にサブフォルダ(red/gren/blue/yellow)、それぞれ赤/緑/青/黄色のボール画像があります(図2‐22)。各フォルダに百枚程度、計数百枚のボール画像があります。ちなみにこれらは「学習用画像セット」の一部を推論用に振り分けたものです。 |
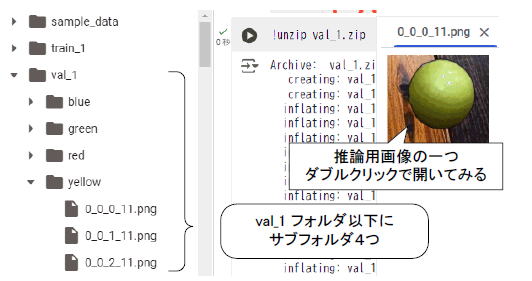
図2‐22 推論用画像は数百枚(学習用は数千枚)
●ラベルリストには各画像の「正解」が書かれている
TestBalls.csvもノートブックにアップロードしましょう。ダブルクリックして中身を見ると図2-23のように classID(属性値、0なら赤色)やpath(ファイル名と場所)が書いてあります。このファイルは「ラベルリスト」と呼ばれ、各画像がどのような属性(この場合は色)を持つかが書かれています。推論プログラムはこれを見て正解/不正解を判定します。 |
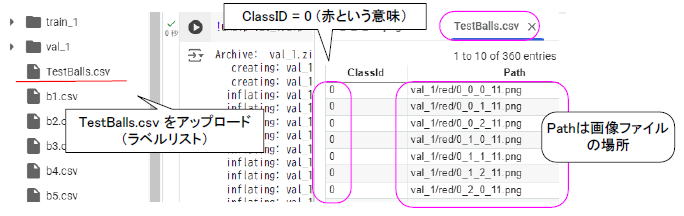
図2‐23 ラベルリストには各画像の「正解値」が書いてある
●属性値(Actual)と推論値(Pred)が一致すれば正解ということ
balls_float_pred.pyは推論用プログラムです。学習済みモデル(重み係数やバイアスのCSVファイル、W1〜W6.csv, b1〜b6.csv)を読み込んでCNNの推論を行います。図2‐24のようにアップロードして実行しましょう。
すると図2‐25のように推論用画像の一部が表示されます。それらの下には属性値(Actual)と推論値(Pred)が書かれますが、正解なら緑字、不正解なら赤字になります。 |
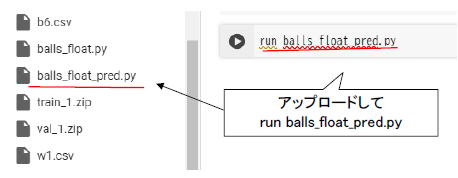
図2‐24 推論用プログラムの実行)
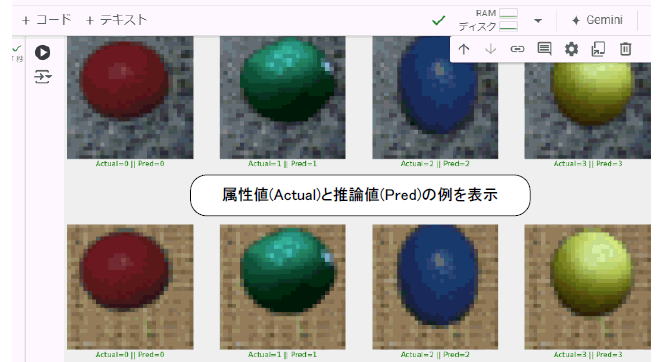
図2‐25 推論結果が一部例示される。これらはすべて正解
●上の方にスクロールしてTest Data Accuracyを探す
正解率は100%になっており(図2‐26)、これは推論用画像(数百枚)が全部正解だったということです。ただし、正解率はW1〜W6.csv, b1〜b6.csvによって(すなわち学習用プログラムを走らせるたびに)微妙に変わるので注意しましょう(100%にならない場合もある、*5)。 |

図2‐26 Test Data Accuracyに正解率
次のページへ
目次へ戻る |