1-03 学習→推論してみる(認識率98%台)
●コーディングもKaggleを参考にする
データセットが準備できたところで、いよいよPythonのコーディングに取り掛かります。図1‐11の上のサイトGTSRB - CNN (98% Test Accuracy)をクリックしましょう。
すると次のようにPythonのコードとその説明が現れます。 |
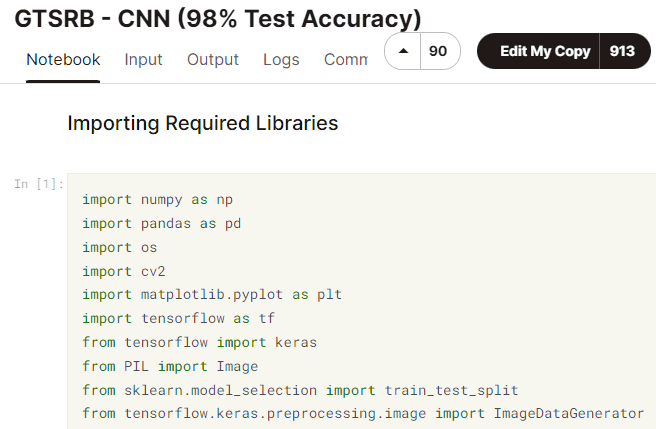
図1-21 GTSRB - CNN (98% Test Accuracy)のPythonコード
●Anacondaプロンプトからjupyter labで実行環境
Pythonの実行にはAnacondaなどを使うとよいでしょう。上記サイト上のコードを上から順番に実行していきますが、先ほどダウンロードしたデータセットが図1‐22のAssigning
Pathに存在するか確認しましょう。 |
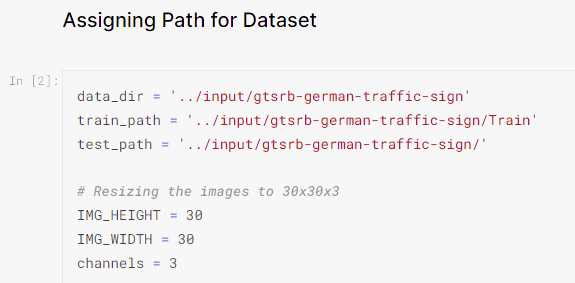
図1-22 データセットの場所(Trainフォルダなど)を確認する
●学習には時間がかかる
学習はfit関数で行います。20〜30分かかると思います。図1‐23のようにEpochが30/30まで進んで終わりです。 |

図1-23 Epochが進むたびに精度が上がっていく。
●学習はTrainフォルダ、推論はTestフォルダを使う
学習が終わったら自動的に推論に移ります。図1‐24ではAccuracy(正解率)が98.06%になっています(*1)
(*1)毎回、学習の仕方(画像をとる順番など)が変わるので正解率は微妙に変わる。 |

図1-24 正解率はおおむね98%台
●Pythonでの道路標識の認識はこれで終わり
最後に正解・不正解の例が表示されます(図1‐25)(*2)。各画像の下にActual(正解)とPred(推論結果)が書かれています。
(*2)同図でははR(赤)とB(青)の成分が逆になっているので注意(Pythonコードのバグ)。
|

図1-25 これらはすべて正解している(RとBが逆なので色がおかしいが)
●以上のPythonコードを一体化してここに置きます(若干変更有り、under Apache 2.0 license)
Datasetをダウンロード→解凍し、図1‐26の場所にmain_float.pyを置いて実行します(*2)。学習→推論で30分以上かかると思います。
(*2)Jupyter LabのバージョンによってはAdam関数のところ変更が必要です |
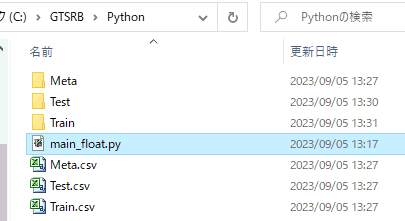 図1‐26 図1‐26
最初のページへ
目次へ戻る
|