0-02 同じHDLを複数の認識対象に使い回す
●キーワードはHDLの共通化
「学習済みモデルの作成」から始めることにより、ニューラルネットワークの形状を「共通化」することができます。すなわち図0‐10のように同じFPGAボードを使って違う認識対象を処理することができ、またFPGAに書き込むHDL(Harware Description Language, ハードウエア記述言語)もほぼ共通化できます(*1)
(*1)重み係数とバイアスの値(それらを格納するROMファイル)だけを変える。 |
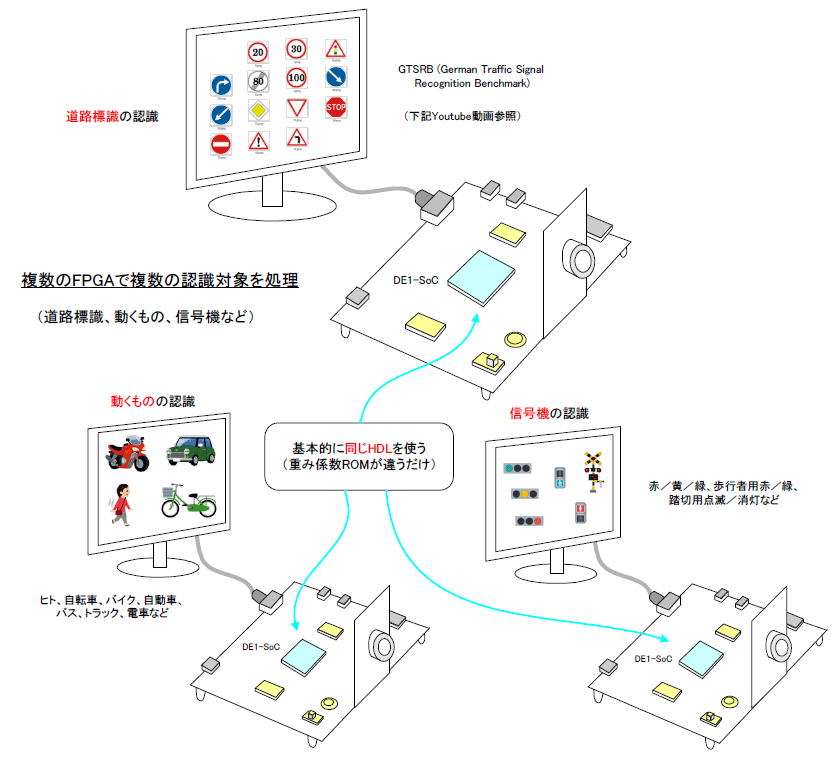
図0-10 ニューラルネットワークの形状を共通化した結果、HDLを使い回せる!
●認識のブロックは30×30画素
上図の一番上、道路標識の認識のようすはこのサイト(Youtube)で確認できます。VGAには動画とともに「認識結果」が緑色で上書きされています。
また緑色で「格子模様」が書かれています(図0-11)。各格子は30×30画素であり、標識がその中に収まれば認識されます。 |

図0-11 30x30の格子に入ったら認識される(背景にうっすらと標識が見える)
●一画面640x480画素をブロック単位に分けて認識
カメラからの動画はVGAサイズであり、640×480画素です。したがって図0-12のように横方向に20ブロック、縦方向に16ブロック、全部で320ブロックをリアルタイム認識します(同図に示すように横方向は2ピクセルの隙間がある)。 |
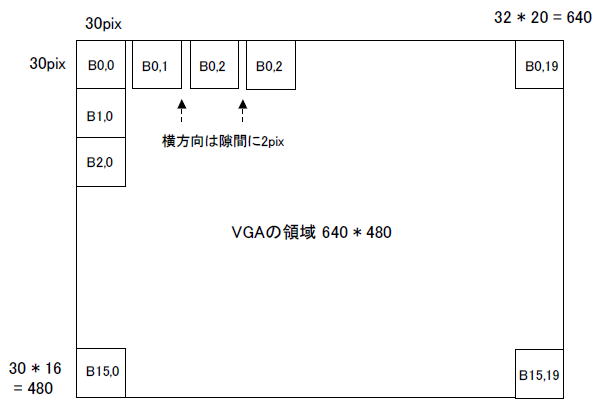
図0-12 ブロックは20x16 = 320ある。全ブロックをリアルタイム認識する
●認識対象を変えても同様に処理する
図0-10の左下の「動くものの認識」、右下の「信号機の認識(*2)」も同様に、1ブロック30x30画素、横20ブロック、縦16ブロック、全320ブロックの認識を行います。
(*2)ここに信号機の認識のようす。重み係数を変えるだけなので簡単に移植できる
●大きく見えても写真やビデオを撮ってみると意外と小さく映っている
1ブロック30x30画素は小さいように思うかもしれませんが、ドライブレコーダーなどで撮った画像に映る物体は意外と小さく、それくらいの画素範囲に収まっているケースが多いと思われます。 |
次のページへ
目次へ戻る
|