2-05 整数化したPythonで認識率97%台
●整数化したらどれくらい認識率が変わるのか
本章では図2‐20のように各層を整数化しました。これらの係数を使ってPythonを走らせて推論してみます。 |
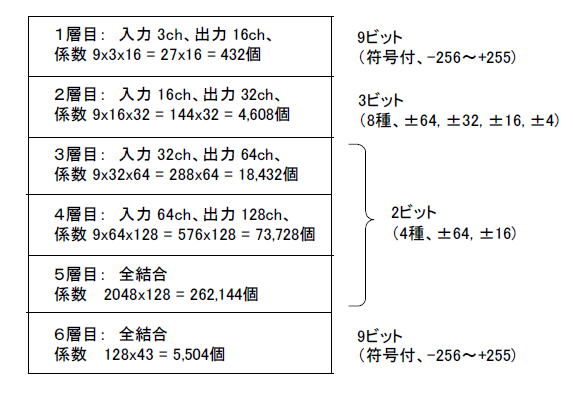
図2‐20 整数化して更に係数の種類も減らしている
●意外と劣化していない
Jupyter Lab上で走らせると図2‐21のように、正解率は97.498%となりました。小数で演算した際は98%台だったので、1%程度の劣化になりました。 |
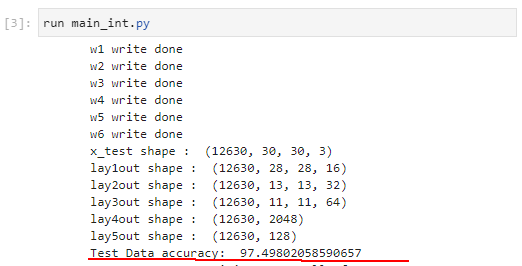
図2‐21 テスト画像を推論した結果97%台
●FPGAで使うために係数をセーブしておく
1層目から6層目までの重み係数はw1_int〜w6_int.csv、バイアスはb1_int.csv,
b6_int.csvにセーブされます。図2‐22では3層目の係数とバイアスをCSVファイルに落としています。 |

図2‐22 get_weights()で重みやバイアスを取り出してセーブ
●整数化したPythonコードをここに置きます。正解率は97%台。main_int.pyを実行すると以下のファイルが生成されます。
| 整数化された重み係数 |
w1_int.csv, w2_int.csv, w3_int.csv, w4_int.csv, w5_int.csv, w6_int.csv |
| 整数化されたバイアス |
b1_int.csv, b2_int.csv, b3_int.csv, b4_int.csv, b5_int.csv, b6_int.csv |
●整数化前の重み係数やバイアスはこれを使うと良い
main_float.pyで学習モデル(係数やバイアス)をセーブし、main_int.pyでそれをロードして整数化します。
正解率は学習のたびに微妙に変わるので、係数やバイアスを整数化する際は、元々高い正解率のものを使うほうが有利です。wei0307.zipを展開するとw1〜w6, b1〜b6があるのでそれらを使いましょう。 |
最初のページへ
目次へ戻る
|