20-01 MNISTデータセットを使った手書き文字認識
●今度は「手書き文字の認識」。係数やバイアスのHDLを変えるだけ!
「道路標識の認識」を「信号機の認識」、「人・自動車・バイクの認識」、「コンクリートのひび割れの認識」と変更しましたが、さらに「手書き文字の認識」を試みます。
本章では図20‐01のように黒板にチョークで数字を書き、それをCMOSカメラ+FPGAでリアルタイム認識させます(緑色で認識結果)。 |

図20-01 認識結果を緑色で動画に上書き表示
●MNISTというデータセットを使う
学習や推論に使う画像は、図20‐02のような「MNISTデータセット」になります。黒板+白いチョークの文字認識ですから、ちょうど都合の良いデータセットといえます。 |
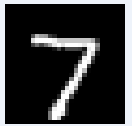 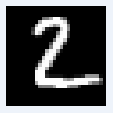 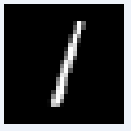 
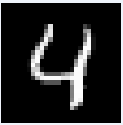 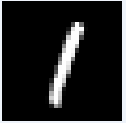 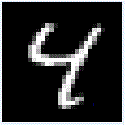 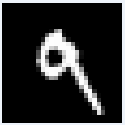
図20-02 MNIST推論用画像の最初の8枚。白黒、28×28画素になる
●MNISTをダウンロードしてみると・・・
MNISTデータセットは学習用に60,000枚、推論用に10,000枚の画像を含みます。それらのダウンロードはKeras(*1)が用意する読み込み関数で行います。
(*1)ニューラルネットワークのライブラリ。Tensorflow上で動くようです。
データセットには「画素値」と「ラベル値」が存在し、前者は画像そのもの、後者はその画像がどのクラス(0~9、すなわち正解値)に属するかを示すものです。
画像はクラスごとに分けられているわけではなく、0~9までの画像がランダムに格納されています。たとえば推論用画像は図20‐02のように、最初が数字の7、次が2、その後
1, 0, 4, 1, 4, 9...と続きます。 |
●Pythonで画像ファイルを分類する
本企画では画像をクラスごとに分けてフォルダに置きます。したがって学習・推論の前処理として、次のようなPythonプログラムを実行します。
①MNISTデータセットをダウンロードする。
②各画像をPNG形式でファイルに落とす。
③各画像をクラス(ラベル値)ごとにフォルダに分ける。
上記の操作をするPythonプログラム(これ)を適当なディレクトリで実行すると(数分かかる)、図2‐03のように0~9のフォルダが現れます(*2)。
(*2)Pythonプログラムはこのサイトを参考にしました。 |
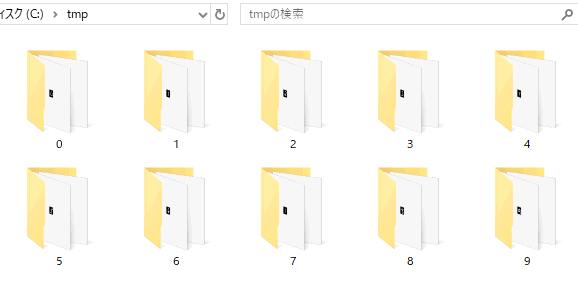
図20-03 各フォルダに学習用画像がある。合計60,000枚
●”0”フォルダには数字の”0”の画像がある
各フォルダ内には図20‐04のようにフォルダ名に相当する数字の画像が入っています。それぞれ約6,000個、10フォルダで合計60,000の画像があります。これらは「学習用」です。 |
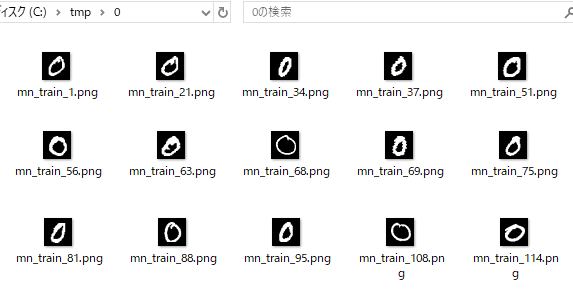
図20-04 Pythonで画像をファイル化(PNG)→ラベル値で分類
●推論用画像もPythonで分類する
「推論用」の画像に対しても同じことを行います。このPythonプログラムを実行すると0~9のフォルダが現れ、それらに相当する数字の画像が約1,000個づつ、10フォルダで合計10,000個の画像が存在します。 |
次のページへ
目次へ戻る
|