8-04丂vgg-5, 6, 7憌栚偺VHDL壔
仠5憌栚偼弌椡256ch偱32暲楍
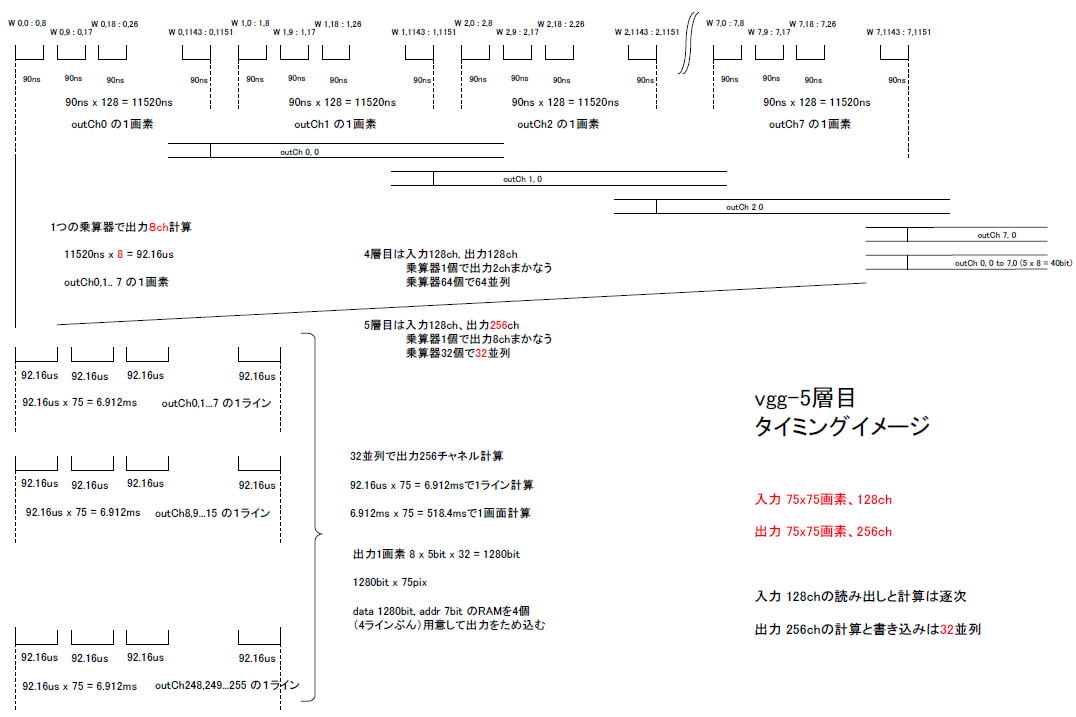
丂恾8乚61偵vgg-5憌栚偺僞僀儈儞僌偺僀儊乕僕傪帵偟傑偡丅
丂5憌栚偺擖椡偼128ch偱偡偑丄弌椡偼256ch偵側傝傑偡丅慜憌傑偱偲摨偠傛偆偵丄擖椡偼拃師張棟丄弌椡偼暲楍張棟偲偟傑偡偑丄偙偙偱偼32暲楍偵偟傑偡丅
丂偡側傢偪1偮偺忔嶼婍偱弌椡傪8ch寁嶼偡傞偙偲偵側傝丄偦偆偡傟偽恾8乚61偺嵍偵偁傞傛偆偵outCh0,1,2,... 7偺1儔僀儞偑6.912ms偱寁嶼偱偒丄1夋柺偑518.4ms偱寁嶼偱偒傑偡丅偙偺傛偆偵1夋柺寁嶼偵偐偐傞帪娫傪奺憌偦傠偊偰僷僀僾儔僀儞壔偵旛偊傑偡丅 |
恾8-61丂vgg-5憌栚偺僞僀儈儞僌偺僀儊乕僕
仠8ch亊32暲楍側偺偱弌椡256ch
丂恾8乚61偺忋抜偼outCh0,1,2,... 7傪寁嶼偡傞傛偆偡偱偡丅偙傟傜弌椡8ch偼1屄偺忔嶼婍偱乽拃師揑偵乿寁嶼偝傟傑偡丅偟偨偑偭偰1夋慺偺寁嶼偵偐偐傞婜娫偼90ns
x 128 x 8 = 92.16us偵側傝傑偡丅1儔僀儞75夋慺側偺偱92.16us x 75 = 6.912ms偱1儔僀儞偺寁嶼丄1夋柺75儔僀儞側偺偱6.912ms x 75 = 518.4ms偱1夋柺偺寁嶼偑廔傢傝傑偡丅
丂侾偮偺忔嶼婍偱8ch傇傫寁嶼偡傞偨傔丄outCh0偺1夋慺丄outCh1偺1夋慺丄outCh2偺1夋慺丄...
outCh7偺1夋慺傪偦傟偧傟暿偺僞僀儈儞僌乮11520ns偍偒乯偵儔僢僠偟偰庢傝弌偟丄峏偵傕偆堦搙儔僢僠偟偰僞僀儈儞僌傪懙偊傑偡乮恾8乚61偺塃偺曽偵偁傞乽outCh
0,0 to 7,0乿乯丅
丂忔嶼婍乮價僢僩僔僼僩宆乯偑32屄暲楍偱8ch偯偮寁嶼偡傞偺偱弌椡偼256ch偵側傝傑偡乮擖椡偼128ch乯丅夋慺悢偼擖椡偲堦弿偱75亊75偱偡丅 |
仠4憌栚偺弌椡偑5憌栚偺擖椡偵側傞
丂4憌栚偺僔儈儏儗乕僔儑儞寢壥relu.out偺柤慜傪曄偊偰lay5.in偲偟丄偦傟偑5憌栚偺擖椡偵側傝傑偡丅恾8乚62偺傛偆偵RAM_X1_0乣3乮擖椡僶僢僼傽丄4儔僀儞傇傫乯偵lay5.in偺撪梕偑彂偒崬傑傟傑偡丅
丂conv_layer5偼擖椡僶僢僼傽偐傜偺夋憸傪張棟偟偰RAM_X2_0乣3乮弌椡僶僢僼傽丄4儔僀儞傇傫乯偵彂偒崬傒傑偡丅1儔僀儞75夋慺側偺偱傾僪儗僗偼128丄弌椡256ch側偺偱僨乕僞暆偼5bit
x 256 = 1280bit偵側傝傑偡丅 |
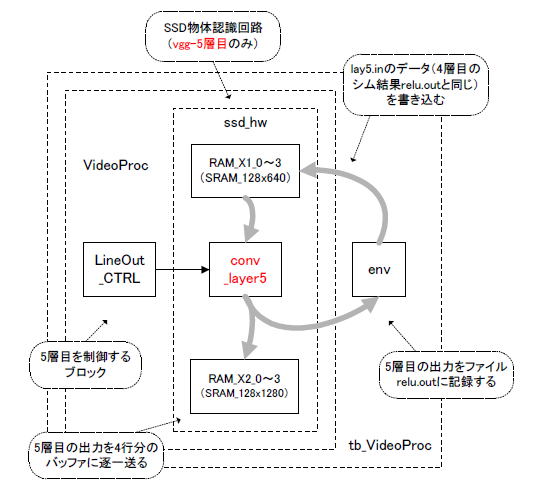
恾8-62丂5憌栚偺僽儘僢僋恾
師偺儁乕僕傊
栚師傊栠傞 |