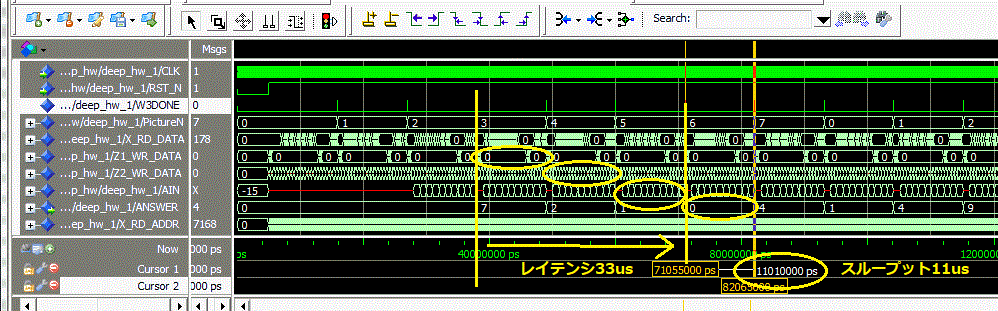
 図3-47 スループットとレイテンシを測る
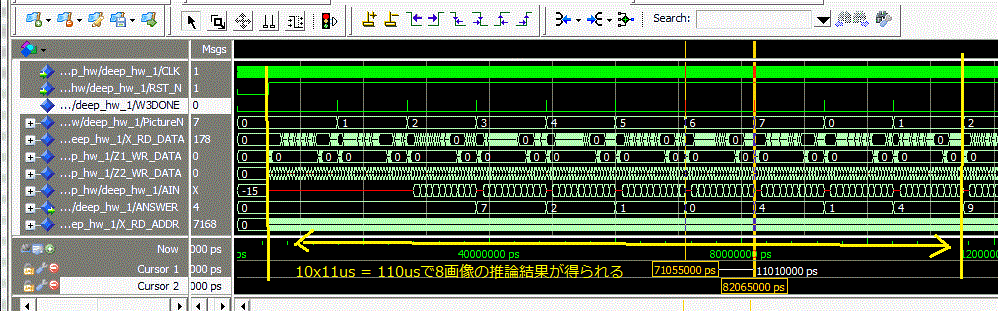 図3-48 画像の枚数が少ないとレイテンシの影響が大きくなる 表3-31 画像の枚数が多いとレイテンシの影響が少なくなる
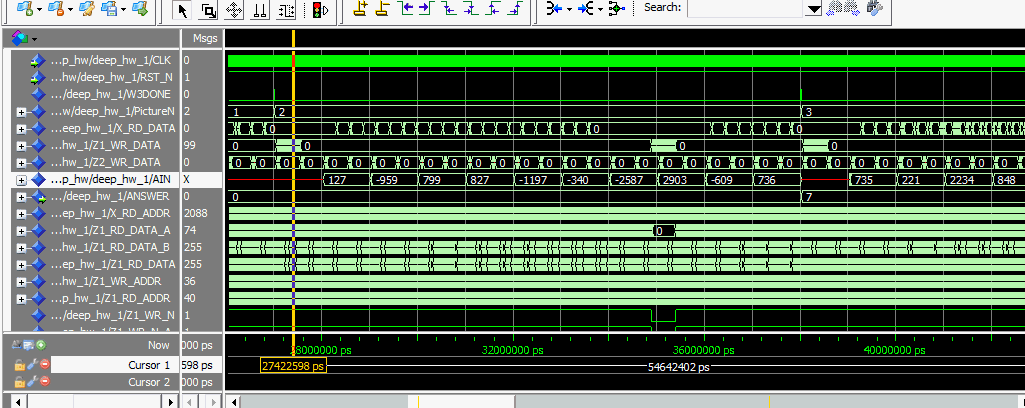 図3-49 演算結果や途中経過も確認
表3-32 41.9倍も高速になった!(演算時間とサイクルはMNIST画像1枚あたり)
最初のページへ 目次へ戻る |
||||||||||||||||||||||||||||||||||||||||||||||||||||
図3-47 スループットとレイテンシを測る
図3-48 画像の枚数が少ないとレイテンシの影響が大きくなる 表3-31 画像の枚数が多いとレイテンシの影響が少なくなる
図3-49 演算結果や途中経過も確認
表3-32 41.9倍も高速になった!(演算時間とサイクルはMNIST画像1枚あたり)
最初のページへ 目次へ戻る |
||||||||||||||||||||||||||||||||||||||||||||||||||||