6‐04 積和演算のHDLを書く
●ハードウエア記述言語VHDLで書いてみる
図6‐13(a)の積和演算回路をHDL化すると図6-16のようになります。
muloutは画素データとフィルタ係数を掛け合わせたもので、こう記述すると論理合成時に乗算器に割り当てられます。乗算により遅延が大きくなるので、同図のようにラッチしてmulout_dlyとします。
mulout_dlyは加算器に入力されます。そして加算結果addoutを1サイクル遅延させたaddout_dlyを加算のもう一つの入力とすれば、累積器を構成できます。
加算結果addoutをCO9=2のタイミング(addout_dly_clr)でラッチすれば積和結果MATMULOUTを取り出すことが出来ます。 |

図6-16 積和演算器のHDL (dotpro.vhd)
●出力16chは並列演算で
1層目は入力は3chですが、出力はこのように16chあります。それらは16並列で演算するので、上記の積和演算器(dotpro)を16個インスタンス化します(図6‐17)。このようにdotpro_00,
01, ... 15と名前を付けるだけでそれら16個は並列動作します(*1)。
(*1)マイコンのように上から順番に動かすのではなく、それぞれ勝手に動く。HDLは”プログラム”ではなく”回路”である |
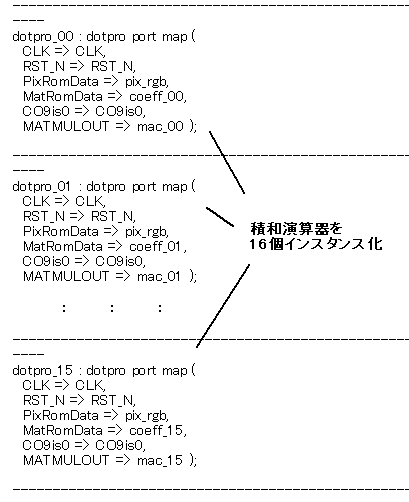
図6-17 これで16個並列動作する(conv_layer1.vhd)
●積和の後の処理
これを見ると積和演算の後に、truncate/plusBias/Reluがあります。図6‐18はバイアスを加算する部分のHDLです。バイアスの値はここで生成したdataB.txtを貼り付けたものです。 |

図6‐18 バイアスを足す部分(conv_layer1.vhd)
●ハードのリソースは限られる。ビット数を減らす工夫が必要
図6‐19はtruncateの部分で下位11ビットを切り捨てています(切り捨てる理由はここ)。その下はReLUの部分で負の値は0、正の値はそのままですが、31でリミッタをかけて5ビットの範囲に収めます(それもここ参照)。 |

図6‐19 出力16chそれぞれ同時に処理(conv_layer1.vhd)
最初のページへ
目次へ戻る
|