6‐03 積和演算の回路図とタイムチャート
●積和演算の定番回路
畳み込みには
積和演算器
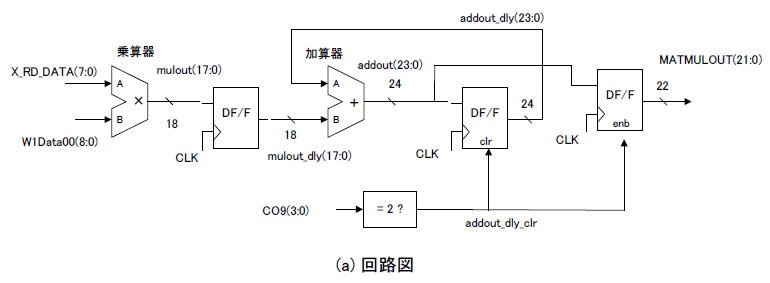
が必要です。図6‐13(a)にその回路図を示します。
X_RD_DATAは画素データ、W1Dataは重み係数でそれらが乗算器に入力されます。その出力muloutはラッチされてmulout_dlyとなり、加算器に入力されます(*1)
(*1)クロックが速い場合(100MHz以上)で動かす場合は乗算器の後にラッチが必要になる(乗算器は遅延量が多いので)。
加算器の出力addoutもラッチされてaddout_dlyとなり、加算器のもう一つの入力にフィードバックされます。これにより累積が実現されます。
図6-13(a) 積和演算器の回路図
●乗算→加算→フィードバックにより積和するようす
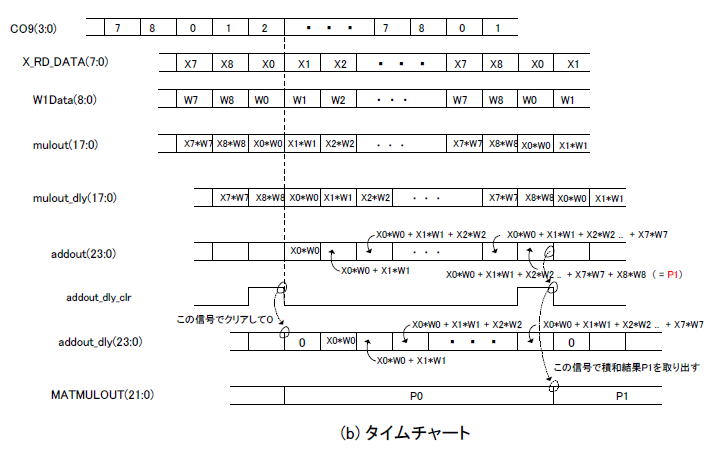
同図(b)は積和演算器のタイムチャートです。CO9は9進カウンタで、これに同期してX_RD_DATA(画素データ)やW1Data(重み係数)が読み出されています(*2)。
(*2)画素データ/重み係数はRAM/ROMに入っており、それらのアドレスはCO9から作られる。アドレス生成に1サイクル、読み出しに1サイクル遅延するので計2サイクル遅延している。
それらが乗算された結果がmulout、更に遅延されてmulout_dlyとなります。
それは加算器に入力され、加算結果addoutが遅延されてaddout_dlyとなります。
addout_dlyは加算器のもう一つの入力となります。結果的にaddoutはmulout_dlyを累積したものになります(*3)
(*3)同図のようにaddout_dlyはaddout_dly_clrでクリアされて0になっている。その後にmulout_dlyを足し込む。addoutが徐々に大きくなっていくのが分かる
最後にaddoutをaddout_dly_clrのタイミングでラッチすれば9個(カーネルが3x3なので)の画素データ&重み係数の
積和結果
MATMULOUTが取り出せます。
図6-13(b) 積和演算器のタイムチャート
●入力は3+1チャネルある
入力が白黒(1ch)の場合はこれで良いのですが、入力は
このように
RGBの
3ch
あります。それらは各々積和されますが、最終的に3つ足し込まれて出力1chが計算されています。
それを鑑みると図6‐14のようなタイムチャートになります。一番上count9は9進カウンタで0〜8までの期間にカーネルが1組読まれて画素データと積和されます。入力chは3つ、さらにダミーchがあるので0〜8までが
4回
繰り返されます。
●出力1画素計算するのに10ns x 9 x 4 = 360ns
カーネルは入力チャネルごとに
4組
あり、それらはin1ChSelで選択されます。その信号が0, 1, 2, 3の期間でR, G, B, Dummyが積和演算され、出力1chの1画素となります。
図6‐14 入力3+1chを足し込んで出力1chを計算するタイムチャート
●出力1ライン計算するのに10ns x 9 x 4 x 28 = 10.08us (
ここ
も参照)
CnnPixCountはin1ChSelが0〜3の期間ごとにカウントアップされ、これは出力画素の横方向の位置(0〜27)を示します(入力は30x30画素なのでカーネルの動く範囲は28×28)。
●出力1画面を計算するのに10ns x 9 x 4 x 28 x 28 = 282.24us(*4)
CnnLineCountはCnnPixCountが0〜27の期間ごとにカウントアップされ、これは出力画素の縦方向の位置(0〜27)を示します。
KernelH/KernelVはそれぞれカーネルの縦/横方向の位置を示します(その下の図参照)。
(*4)28ライン計算するのに282.24usだが、休み時間が入って
320us
になる(
入力が入ってくるタイミン
グと合わせる)
次のページへ
目次へ戻る