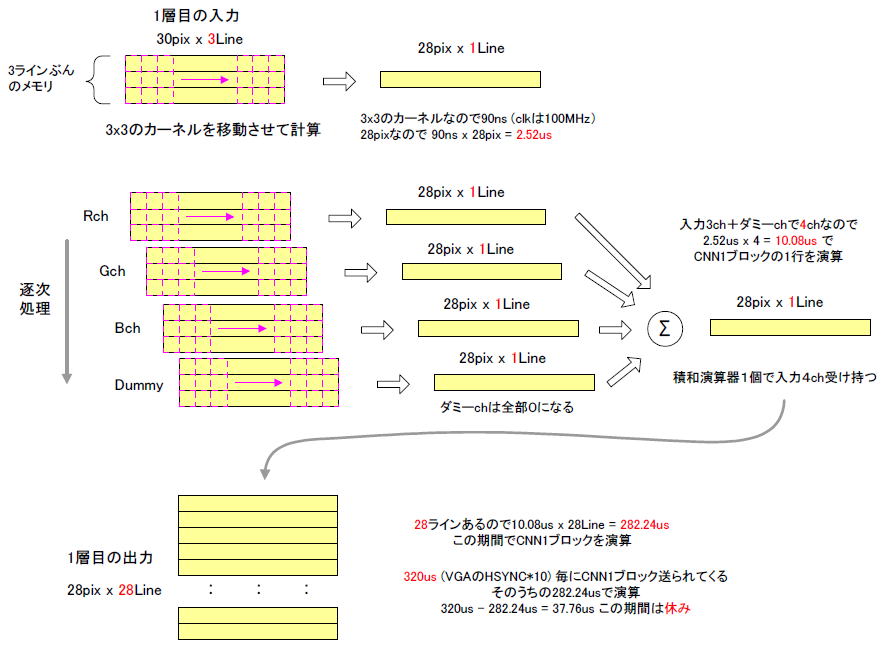
●1ライン演算するのにかかる時間
1層目の入力は30×30画素ありますが、カーネルが3x3なので図5‐24のように、3ラインぶんのメモリがあれば畳み込み演算ができます。同図のように30画素×3ラインから出力の1ライン目(28画素)を計算しますが、それに有する時間は 90ns x 28 = 2.52usです(*1)。
(*1)クロック周波数100MHz (10ns)、9画素読み出すのに90nsかかる
●1層目は入力3ch・・・一つの積和演算器で面倒を見る
1層目では入力はR/G/Bの3チャネルあり、それらを一つの積和演算器が受け持つことにします。ただし、3chでは半端なのでダミーchを追加して4chにします(*2)
(*2)ダミーchはカーネルもデータも0、積和演算結果も0になる |