5乚04 僗儖乕僾僢僩傪寛傔傞乮懕偒乯
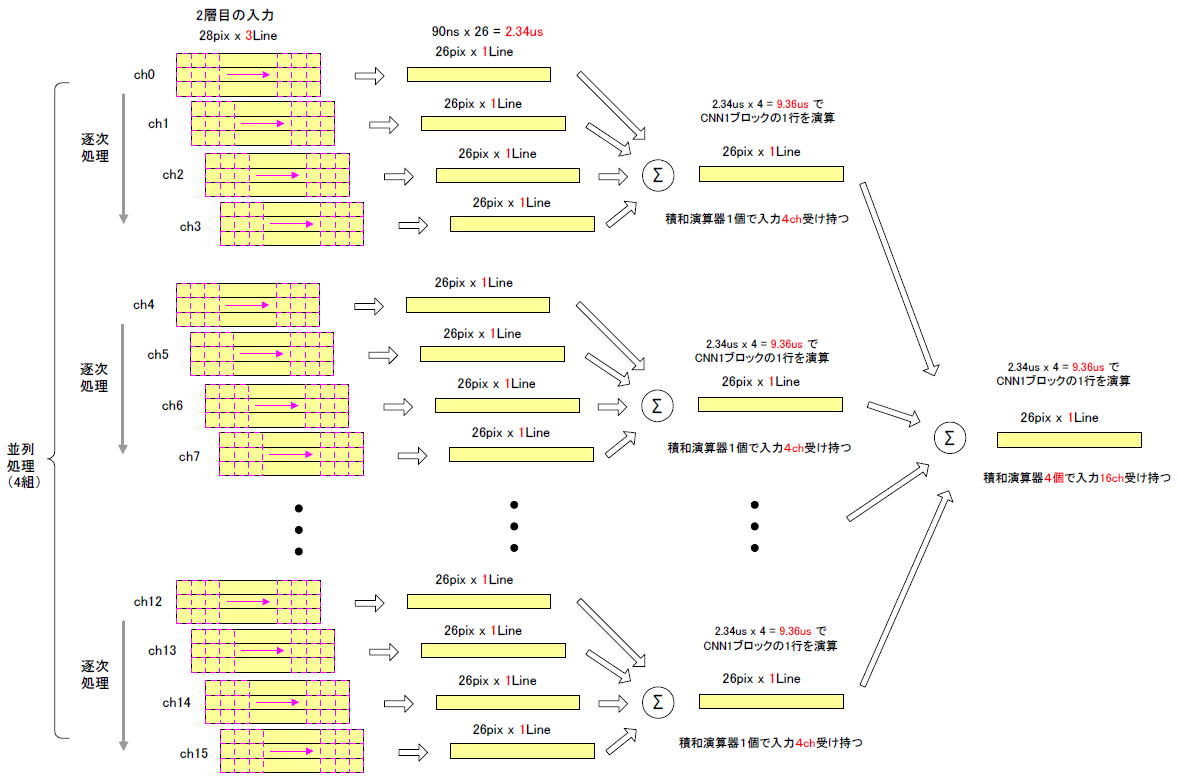
仠2憌栚偼擖椡16ch丒丒丒堦偮偺愊榓墘嶼婍偱偼娫偵崌傢側偄
丂2憌栚偼擖椡16僠儍僱儖偁傝傑偡丅壖偵偦傟傜傪堦偮偺愊榓墘嶼婍偑庴偗帩偮偲偡傞偲丄1憌栚偺4攞偺帪娫偑偐偐傝丄僗儖乕僾僢僩偑栚昗偺320us傪墇偊偰偟傑偄傑偡丅偟偨偑偭偰恾5乚26偺傛偆偵愊榓墘嶼婍傪
4屄
梡堄偟偰丄偦傟偧傟偑
擖椡4ch
傪暘扴偡傞偙偲偵偟傑偡丅
丂摨恾偺堦斣忋偺愊榓墘嶼婍偼擖椡ch0乣3傪庴偗帩偪丄偦傟傜傪
拃師揑
偵張棟偟傑偡丅弌椡偺1儔僀儞偼
26
夋慺側偺偱丄90ns x 26 x
4ch
= 9.36us偱1儔僀儞寁嶼偟傑偡丅
丂偦偺壓偺愊榓墘嶼婍偼擖椡ch4乣7丄師偼ch8乣11丄嵟屻偼ch12乣15傪庴偗帩偪丄奺帺摨條偵張棟偟傑偡丅
恾5-26丂2憌栚偺弌椡1ch偺1儔僀儞傪寁嶼偡傞僀儊乕僕
仠
1儔僀儞
寁嶼偡傞偺偵9.36us (+媥傒帪娫偱10.08us)
丂
4屄偺愊榓墘嶼婍偺弌椡傪懌偟崬傫偱CNN1僽儘僢僋偺1儔僀儞偑寁嶼偝傟傑偡丅偦傟傜偼暲楍偵摦偔偺偱丄偦傟偵偐偐傞帪娫偼摨偠 2.34us x 4ch =
9.36us
偵側傝傑偡丅
丂1憌栚偑1儔僀儞寁嶼偡傞偺偵
10.08us
偐偐傝丄偦偺廃婜偱2憌栚偺擖椡偺
儔僀儞僶僢僼傽偑峏怴
偝傟傑偡丅2憌栚偼1儔僀儞9.36us側偺偱墘嶼偼娫偵崌偭偰偄傑偡乮仏侾乯
乮仏侾乯2憌栚傕奺儔僀儞
10.08us
偱張棟偡傞乮儔僀儞扨埵偱1憌栚偲僞僀儈儞僌崌傢偣乯丅10.08 - 9.36 = 0.72us偼
媥傒帪娫
偵側傞丅
仠26儔僀儞丄32僠儍僱儖寁嶼偡傞偺偵243.36us
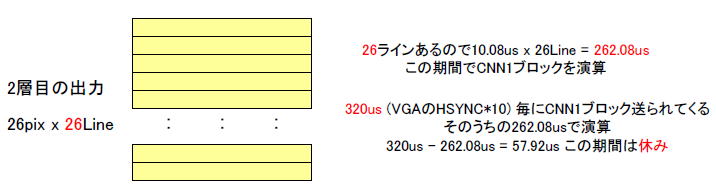
丂恾5乚27偺傛偆偵弌椡偼26亊26夋慺偁傞偺偱丄10.08us x 26Line =
262.08us
偱1夋柺偺墘嶼偑廔椆偟傑偡丅
丂2憌栚擖椡16ch偼忋弎偺傛偆偵4偮偺愊榓墘嶼婍偱暘扴偝傟傑偡丅偦偟偰弌椡偼
32ch
偁傞偺偱恾5乚26偑32慻丄偡側傢偪愊榓墘嶼婍偑4亊32亖
128
屄昁梫偵側傝傑偡乮
偙偙
嶲徠乯丅偦傟傜偼
暲楍
偵摦偔偺偱丄弌椡32ch慡晹偵偐偐傞帪娫偼摨偠偱
262.08us
偵側傝傑偡丅
恾5乚27丂2憌栚偼26儔僀儞偁傞
仠擖椡偑擖偭偰偔傞帪娫撪偵寁嶼偟偰弌椡偡傞
丂奺憌偼
320us
(VGA偺HSYNC偺10夞傇傫乯偺
僗儖乕僾僢僩
偱CNN1僽儘僢僋傪張棟偟側偗傟偽側傝傑偣傫丅
丂2憌栚偼忋婰偺傛偆偵262.08us偱1僽儘僢僋張棟偡傞偺偱丄320us - 262.08us = 57.92us偺梋桾傪傕偭偰廔椆偡傞偙偲偵側傝傑偡丅
仠奺憌暲楍壔偵傛傝僗儖乕僾僢僩偵娫偵崌傢偣傞
丂2憌栚偼128暲楍乮
忔嶼婍128屄
乯偱摦偐偟偰僗儖乕僾僢僩偵娫偵崌傢偣傑偡丅偨偩丄
偙偺FPGA
偵偼忔嶼婍偑87屄偟偐側偄偺偱丄2憌栚偼
偙偺傛偆偵
忔嶼婍傪巊傢側偄乽價僢僩僔僼僩忔嶼乿偱懳墳偟傑偡丅
師偺儁乕僕傊
栚師傊栠傞