5‐04 スループットを決める(続き)
●3層目は入力32chあるが、プーリングで画素が減る
3層目は入力32チャネルありますが、2層目のプーリングにより画素が13×13に減ります。図5‐29のように積和演算器を2個用意して、それぞれが入力16chを分担することにします。
同図の上の積和演算器は入力ch0〜15を受け持ち、それらを逐次的に処理します。出力の1ラインは11画素なので、90ns x 11 x 16ch = 15.84usで1ライン計算します。
その下の積和演算器は入力ch16〜31を受け持ち、同様に処理します。 |
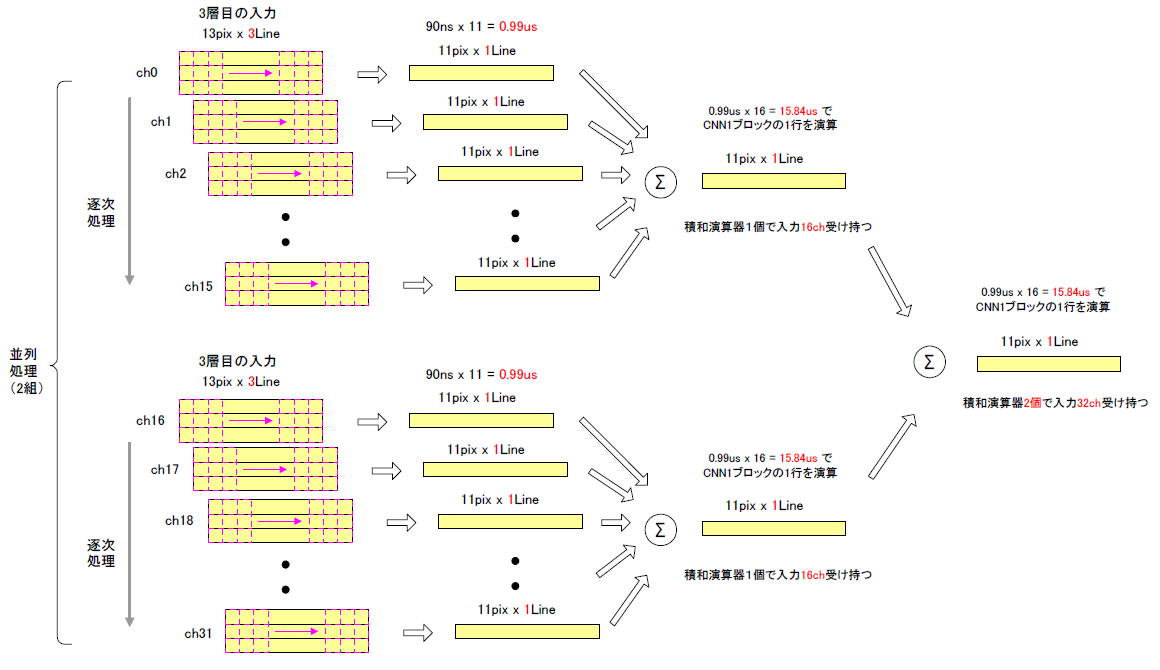
図5-29 3層目の出力1chの1ラインを計算するイメージ
●1ライン計算するのに15.84us (+休み時間で20.16us)
2個の積和演算器の出力を足し込んでCNN1ブロックの1ラインが計算されます。それらは並列に動くので、それにかかる時間は同じ
0.99us x 16ch = 15.84us になります。
1層目が1ライン計算するのに10.08usかかります。そして2層目はプーリングがあるので1ライン20.16usとなり、その周期で3層目の入力のラインバッファが更新されます。3層目は1ライン15.84usなので演算は間に合っています(*1)
(*1)3層目は各ライン20.16usで処理する(ライン単位で2層目とタイミング合わせ)。20.16 - 15.84 = 4.32usは休み時間になる。
●11ライン、64チャネル計算するのに221.76us
図5‐30のように出力は11×11画素あるのでさらに11倍の時間がかかり、20.16us
x 11Line = 221.76us で1画面の演算が終了します。
3層目入力32chは上述のように2つの積和演算器で分担されます。そして出力は64chあるので図5‐29が64組、すなわち積和演算器が2×64 =128個必要になります(ここ参照)。それらは並列に動くので、出力64ch全部にかかる時間は同じで221.76usになります。 |
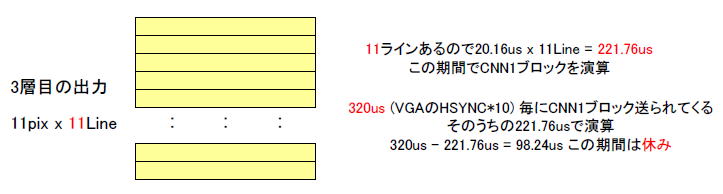
図5‐30 3層目は11ラインある
●入力が入ってくる時間内に計算して出力する
各層は320us (VGAのHSYNCの10回ぶん)のスループットでCNN1ブロックを処理しなければなりません。
3層目は上記のように221.76usで1ブロック処理するので、320us - 221.76us
= 98.24usの余裕をもって終了することになります。 |
●各層並列化によりスループットに間に合わせる
3層目は128並列(乗算器128個)で動かしてスループットに間に合わせます。3層目も2層目と同様、乗算器を使わない「ビットシフト乗算」です。 |
次のページへ
目次へ戻る
|