8乚01丂忯傒崬傒3憌栚偼擖椡32ch丄弌椡64ch
仠3憌栚偼忔嶼婍128屄偱墘嶼
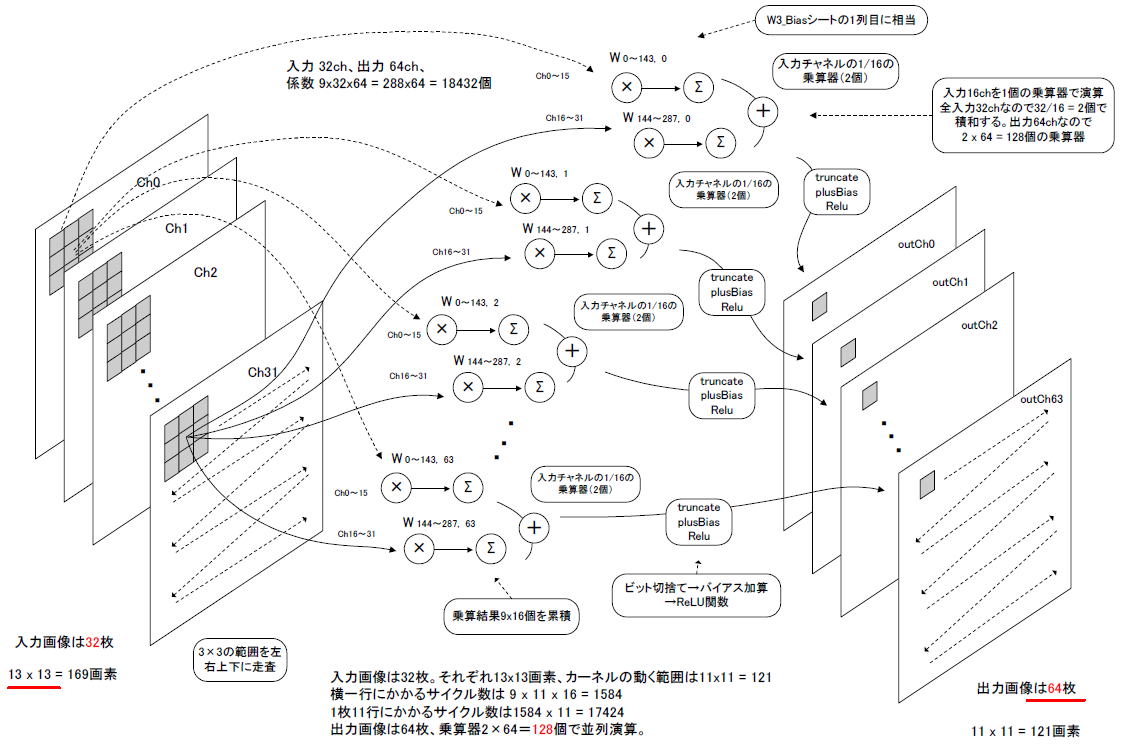
丂恾8乚01偼3憌栚偺墘嶼僀儊乕僕偱偡丅擖椡32僠儍僱儖傪16ch偯偮2慻偵暘偗傑偡乮偙偙嶲徠乯丅偦偟偰Ch0乣15傪1屄偺愊榓墘嶼婍偱傑偐側偄傑偡丅Ch16乣31傕1屄偱傑偐側偄丄寁2屄偺愊榓墘嶼婍偱弌椡1僠儍僱儖傪寁嶼偝偣傑偡丅
丂弌椡偼64僠儍僱儖偁傞偺偱愊榓墘嶼婍偼崌寁2亊64亖128屄偵側傝丄128暲楍偱墘嶼偝傟傑偡丅忯傒崬傒偺寢壥丄弌椡夋憸偼堦夞傝彫偝偔側傝11亊11夋慺偵側傝傑偡丅 |
恾8-01丂3憌栚偼忔嶼婍偑128屄昁梫偵側傞 仺 價僢僩僔僼僩偵傛傞忔嶼丄學悢偼4庬椶
仠忔嶼婍傗ROM偺愡栺
丂3憌栚偼忔嶼婍偑128屄昁梫偵側傞偺偱丄偙偺憌傕乽價僢僩僔僼僩偵傛傞忔嶼乿傪峴偄傑偡丅傑偨廳傒學悢偼係庬椶(+64, +16, -16, -64)偵廤栺偟傑偡丅偙傟偵傛傝ROM偺價僢僩悢傪嶍尭偡傞偙偲偑偱偒傑偡丅
仠1儔僀儞丄1夋柺偺墘嶼偵偐偐傞帪娫
丂擖椡夋憸偼13亊13側偺偱僇乕僱儖乮3x3乯偺摦偔斖埻偼11亊11偵側傝傑偡丅偟偨偑偭偰墶堦峴偵偐偐傞僒僀僋儖悢偼
9 x 11 x 16ch = 1584偱偡乮仏侾乯丅
乮仏侾乯堦偮偺忔嶼婍偱擖椡16ch傪傑偐側偆丅偦傟傜偼拃師揑偵張棟偝傟傞偺偱x16ch偺僒僀僋儖偑偐偐傞
丂弌椡1枃11峴偵偐偐傞僒僀僋儖悢偼 1584x 11 = 17424丄弌椡偼暲楍偱墘嶼偝傟傞偺偱丄64枃偵偐偐傞僒僀僋儖悢偼摨偠17424偵側傝傑偡丅僋儘僢僋100MHz側傜丄1峴偵15.84us丄1枃偵174.24us偐偐傝傑偡丅 |
仠僷僀僾儔僀儞側偺偱僗儖乕僾僢僩偵娫偵崌傢偣傞
丂2憌栚偑1儔僀儞弌椡偡傞偺偵20.16us偱偟偨乮僾乕儕儞僌偵傛傝10.08us x 2偵側傞)丅3憌栚偑1儔僀儞弌椡偡傞偺偵15.84us側偺偱丄僷僀僾儔僀儞揑偵娫偵崌偭偰偄傞偙偲偵側傝傑偡丅傑偨丄偙偙偵偁傞傛偆偵CNN偺1僽儘僢僋偼320us偺廃婜偱CNN悇榑夞楬偵擖椡偝傟傑偡丅忋弎偺傛偆偵174.24us偱張棟偡傞偺偱丄偙傟傕娫偵崌偭偰偄傑偡乮仏俀乯丅
乮仏俀乯2憌栚偲摨婜傪偲傞偨傔丄3憌栚偼1儔僀儞15.84us + 媥傒帪娫 = 20.16us丄1僽儘僢僋174.24us + 媥傒帪娫 = 320us偱弌椡偡傞丅 |
仠學悢ROM偼庤嶌嬈偱HDL壔偡傞偺偼戝曄側偺偱丒丒丒
丂3憌栚偼擖椡32ch丄弌椡64ch側偺偱學悢偺悢偼9亊32亊64亖 18,432屄偵側傝丄2憌栚傛傝4攞憹偊傑偡丅偙傟傜偼ROM偺僨乕僞偵側傝傑偡偑丄偦偺HDL僼傽僀儖偼傕傕偪傠傫VBA偱帺摦惗惉偝偣傑偡丅 |
師偺儁乕僕傊
栚師傊栠傞
|