6‐05 1層目のRAMアクセス(HDL、続き)
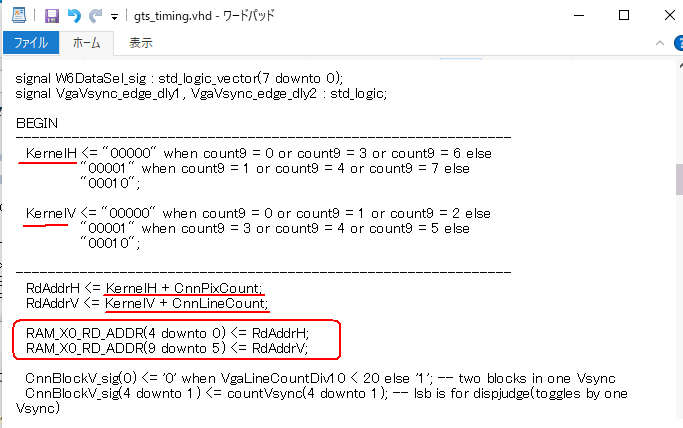 図6-40 このタイムチャートをHDL化(gts_timing.vhd)
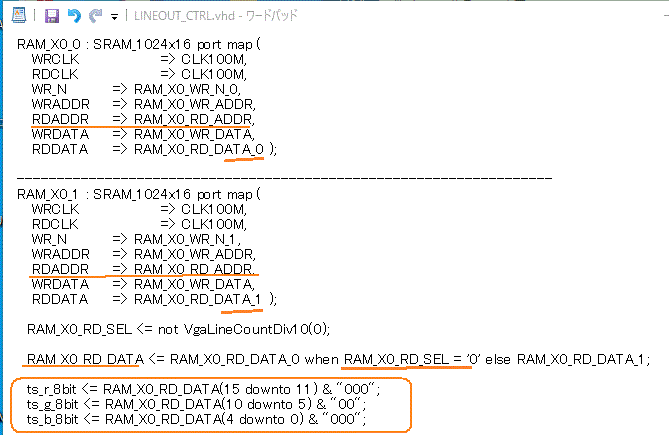 図6-41 バッファが2つ。書いていない方から読みだす(LineOut_Ctrl.vhd)
 図6‐42 出力16chなので積和演算器16個(conv_layer1.vhd)
次のページへ 目次へ戻る |
|||||||
6‐05 1層目のRAMアクセス(HDL、続き)
図6-40 このタイムチャートをHDL化(gts_timing.vhd)
図6-41 バッファが2つ。書いていない方から読みだす(LineOut_Ctrl.vhd)
図6‐42 出力16chなので積和演算器16個(conv_layer1.vhd)
次のページへ 目次へ戻る |
|||||||