8-07 vgg-14, 15層目のVHDL化
●14層目は出力1024chで64並列
図8‐122にvgg-14層目のタイミングのイメージを示します。
14層目の入力は512ch、出力は1024chになります。入力は逐次処理、出力は64並列で計算します。
すなわち1つの乗算器で出力を16ch計算することになり、そうすれば同図の左にあるようにoutCh0,1,2,...15の1ラインが14.00832msで計算できます。 |
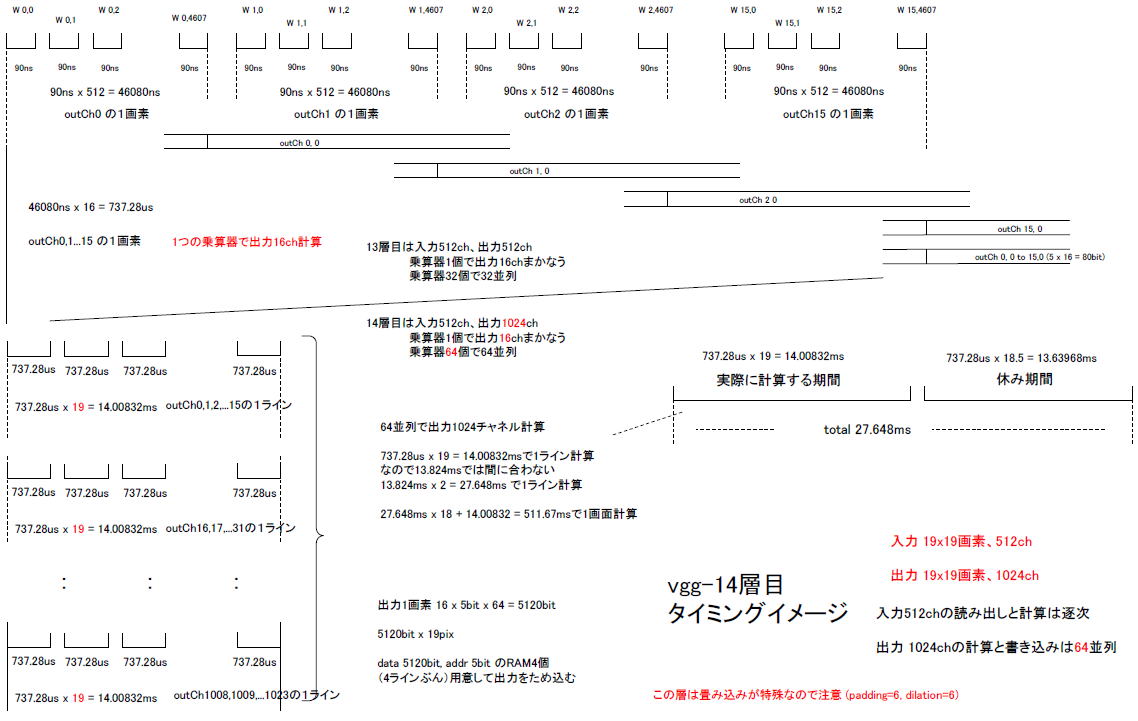
図8-122 vgg-14層目のタイミングのイメージ
●16ch×64並列なので出力1024ch
図8‐122の上段はoutCh0,1,2,...15を計算するようすです。これら出力16chは1個の乗算器で「逐次的に」計算されます。したがって1画素の計算にかかる期間は90ns
x 512 x 16 = 737.28usになります。
1ライン19画素なので737.28 x 19 = 14.00832msで1ライン計算しますが、同図右にあるように「休み期間」が13.63968msあるので計27.648msで1ライン、1画面19ラインなので27.648ms
x 19 = 525.312msで1画面の計算が終わります。(*1)
「outCh16 to outCh31」、「outCh32 to outCh47」、...「outCh1008 to outCh1023」もそれぞれ1つの乗算器で計算されます。乗算器(ビットシフト型)が64個並列で16chづつ計算するので出力は1024chになります(入力は512ch)。
(*1)実際は27.648ms x 18 + 14.00832 = 511.67msで1画面の計算が終わる。518.4msより少し短い |
●13層目の出力が14層目の入力になる
13層目のシミュレーション結果relu.outの名前を変えてlay14.inとし、それが14層目の入力になります。図8‐123のようにRAM_X1_0〜13(入力バッファ、14ラインぶん、理由は後述)にlay14.inの内容が書き込まれます。
conv_layer14は入力バッファからの画像を処理してRAM_X2_0〜1(出力バッファ、2ラインぶん、次層はカーネルが1x1なので)に書き込みます。1ライン19画素なのでアドレスは32、出力1024chなのでデータ幅は5bit
x 1024 = 5120bitになります。 |
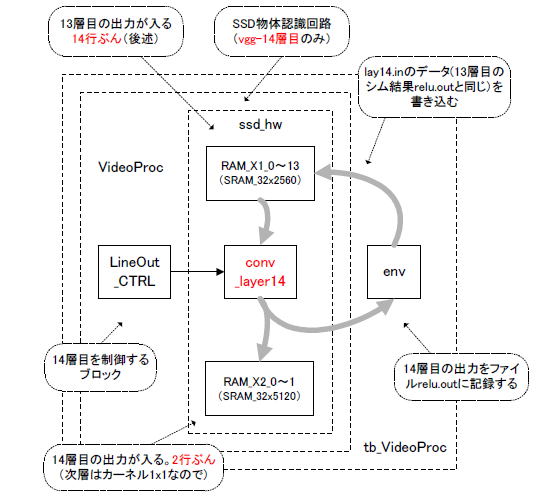
図8-123 14層目のブロック図
次のページへ
目次へ戻る |