7-01丂SSD偺暲楍壔偺尷奅傪扵傞乮懕偒乯
仠偲偙偲傫暲楍壔偡傞偲偳偆側傞偐
丂CNN僒僀僋儖悢偺壓尷偼乽夋慺悢亊9僒僀僋儖乿偵側傝傑偡偑丄偦偺嵺偵昁梫側忔嶼婍偺悢偼偳偆側傞偱偟傚偆偐丅恾7-03偼偙偺
僽儘僢僋恾
偺忯傒崬傒
1憌栚
偺僀儊乕僕偱偡丅偙偺傛偆偵擖椡僠儍僱儖悢亊弌椡僠儍僱儖悢乮3亊64亖
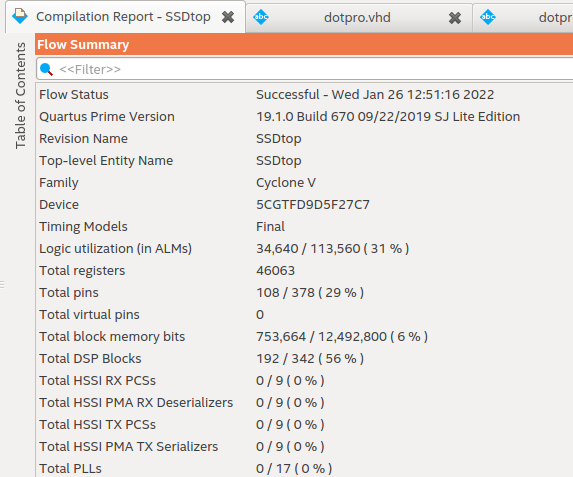
192
屄乯偺忔嶼婍偑偁傟偽乽夋慺悢亊9僒僀僋儖乿偱弌椡慡僠儍僱儖偺慡夋慺偑寁嶼偱偒傑偡丅
丂偙偺
僽儘僢僋恾
偺忯傒崬傒
2憌栚
偼擖椡偑64僠儍僱儖丄弌椡傕64僠儍僱儖偵側傝傑偡丅偟偨偑偭偰64亊64亖
4096
屄傕偺忔嶼婍偑昁梫偵側傝傑偡丅埨壙側FPGA偵偼偦傫側偵忔嶼婍偑側偄偺偱丄
偙偙
偵帵偡傛偆偵乽價僢僩僔僼僩偵傛傞忔嶼乿傪峴偄傑偡偑丄偦傟偱傕4096屄偲側傞偲偨偄偦偆側夞楬婯柾偵側傝傑偡丅
丂丂恾7-03丂嵟戝尷暲楍壔偩偲忔嶼婍偼擖椡Ch亊弌椡Ch屄昁梫
仠1仌2憌栚傪嵟戝尷暲楍壔偟偰傒傞
丂帋偟偵侾丆俀憌栚傪栚偄偭傁偄暲楍壔偟偰傒傑偡丅1憌栚3亊64亖192屄乮偙傟傜偼晛捠偺忔嶼婍乯丄2憌栚64亊64亖4096屄乮偙傟傜偼價僢僩僔僼僩忔嶼婍乯偱HDL傪愝寁偟丄榑棟崌惉偡傞偲恾7-04偺傛偆偵側傝傑偟偨丅
丂偙偺傛偆偵1仌2憌栚偩偗偱儘僕僢僋傪31亾傕徚旓偟偰偄傑偡丅慡晹偱28憌偁傞帠傪峫偊傞偲乮
偙偙嶲徠
乯丄偙偺FPGA偵偼慡慠擖傝愗傝傑偣傫乮仏俁丆係乯
乮仏俁乯Terasic幮Starter Platform for OpenVINO Toolkit偵搵嵹偺Intel幮CycloneV GT 5CGTFD9D5F27C7N傪憐掕丅
乮仏係乯DSP Blocks傪192屄巊梡偟偰偄傞偑丄偙傟偼1憌栚偺忔嶼婍丅2憌栚偼價僢僩僔僼僩宆側偺偱儘僕僢僋偵妱傝摉偰傜傟傞丅
恾7乚04丂1憌栚仌2憌栚偩偗偱Logic傪31亾傕巊偭偰偄傞
仠偁傞掱搙偺乽
拃師壔
乿偑昁梫
丂SSD暔懱擣幆傪嵟戝尷暲楍壔偡傞偲夋憸1枃乮300x300夋慺乯傪900k僒僀僋儖掱搙偱悇榑偱偒傑偡丅偟偐偟忋婰偺傛偆偵FPGA偵擖傝偒傜側偔側傞偨傔丄偁傞掱搙偼乽
拃師張棟
乿偝偣傞昁梫偑偁傝傑偡丅
丂偝偟偁偨傝乽
64攞
拃師壔乿偲偟偰夞楬傪尭傜偟傑偡丅偡側傢偪摨堦偺儕僜乕僗傪64夞帪暘妱偱巊梡偡傞偺偱僒僀僋儖悢偼64攞丄900 x 64 = 栺60M僒僀僋儖偵側傝傑偡丅僋儘僢僋100MHz偱摦偐偡偲10ns x 60M = 栺
600ms
偱夋憸1枃悇榑偱偒傞偙偲偵側傝傑偡丅
仠彨棃揑偵偼傕偭偲暲楍壔偡傞
丂傕偭偲崅懍偵偟偨偄応崌偼乽暲楍
壔乿偲乽FPGA梕検乿偲偺僩儗乕僪僆僼偵側傝傑偡丅乽暲楍壔搙崌乿傪忋偘傞偨傔偵偼尰忬偼崅壙側FPGA偑昁梫偵側傝偦偆偱偡丅偟偐偟彨棃揑偵偼埨壙偱戝梕検側FPGA偑弌偰偔傞偱偟傚偆偐傜偦傟傪懸偮庤傕偁傝傑偡丅
嵟弶偺儁乕僕傊
栚師傊栠傞