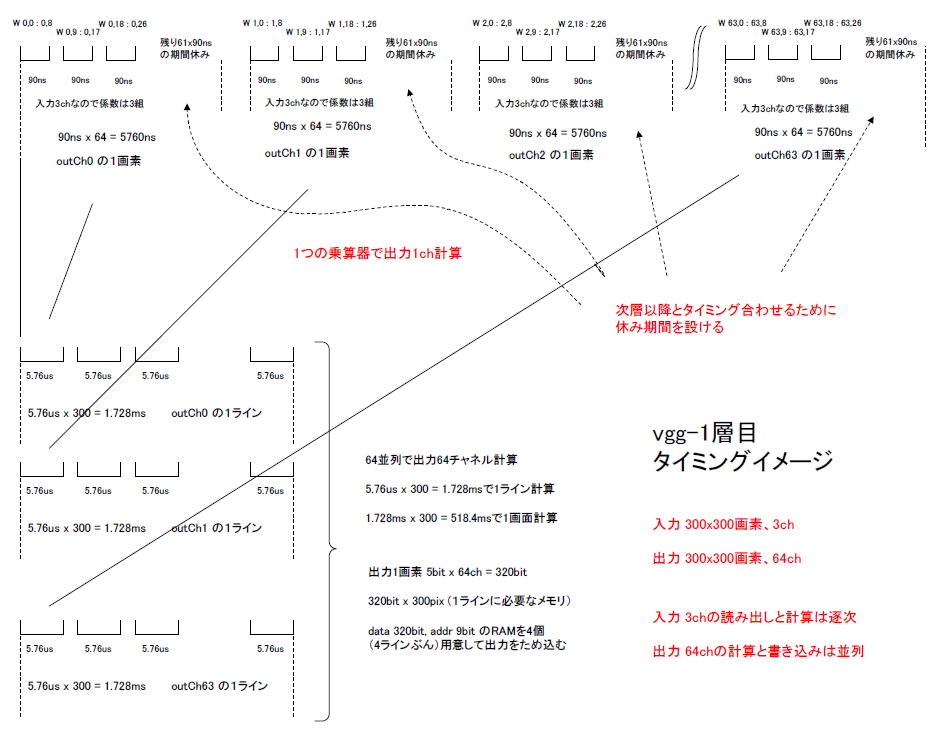
●入力は逐次的、出力は並列的に処理する
図8‐01の左上、「outCh0の1画素」は出力チャネル0の1画素を計算するようすです。
入力は3chありそれらの読出しは逐次的に行います。係数も3chぶんあり、カーネルは3x3=9なので、9x3個の係数(このEXCELのA列の27個)が逐次読みだされ、入力画像と乗算されます。
クロック周期を10nsとすると10ns x 9 x 3ch = 270nsで終わるのですが、次層以降とタイミングを合わせるために10x
9 x 61 = 5490nsの「休み期間」を設け、計5760nsで1画素計算します。
その隣、「outCh1の1画素」は出力チャネル1、その隣は出力チャネル2、最後は出力チャネル63の1画素の計算になります。出力の計算は並列なので、これらは64個の乗算器を使って同時に計算されます(同図の左下)。 |