6‐05 1層目のRAMアクセス(書き方)
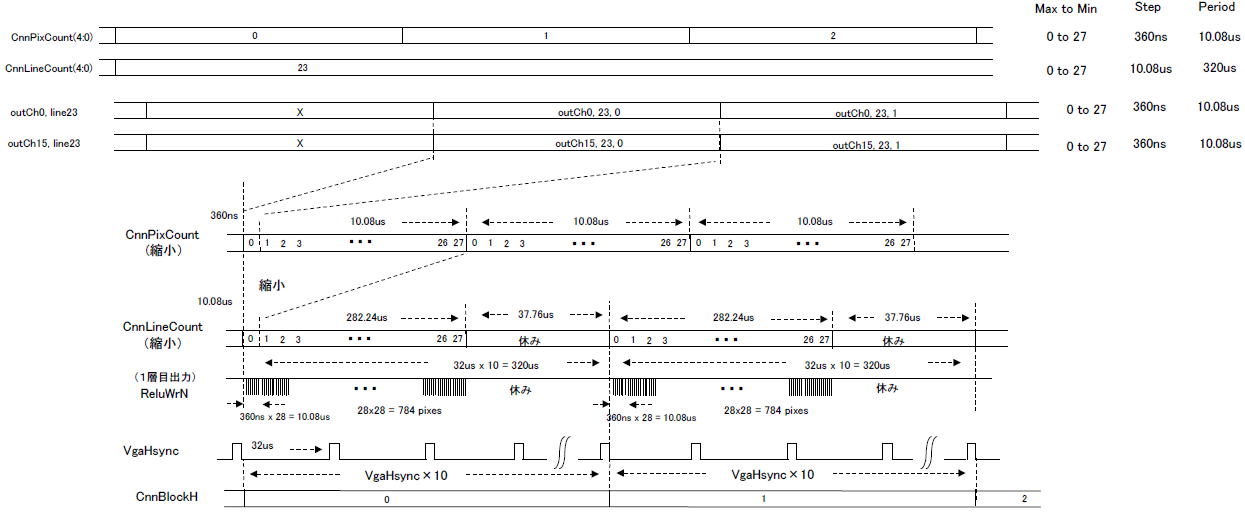
●1画素、1ライン、1画面の計算時間
ここ
で述べたように、出力の1画素は
360ns
で計算されます。図6‐22の時間軸を縮小して図6‐23のCnnPixCount(縮小)とします。その信号は0〜27までカウントアップされるのに 360ns x 28 =
10.08us
かかります。この周期でCnnLineCountがカウントアップされます。
その下のCnnLineCount(縮小)のように、その信号は0〜27までカウントアップされます。10.08us x 28 =
282.24us
かかりますが、CNN1ブロック入力の周期
320us
(VGAのHSYNC10回ぶん)に合わせるので、37.76usの「休み時間」の後に0になります。
一番下のCnnBlockHはCNNのブロックの横方向の位置を示します。横方向は
このように
0〜19までの20ブロックになります。
図6-23 1画面計算は休み時間が入って320us
●
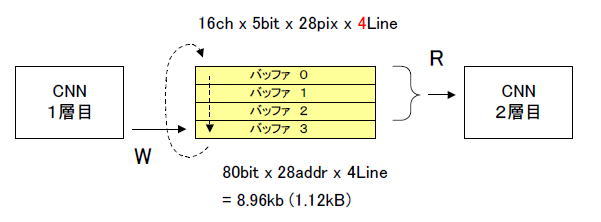
バッファ
は4ラインぶんでFPGAリソースを節約
ここで
カーネルサイズが3×3
ということを思い出しましょう。図6‐24のように1層目の出力は、バッファが4ラインぶんあれば十分なことが分かります。CNNの各層は同図のようにラインバッファ×4でデータの受け渡しが行われます。
図6-24 1層目の出力バッファ。書き方(W)を追いかける読み方(R)
●1層目はラインバッファに書き込む
タイムチャート図6‐23のように、ReluWrN(1層目出力の書き込みイネーブル)がLのときにラインバッファに書き込んでいきます。CNN1ブロックが28×28画素であり、1画素に360ns、1ラインに10.08us、1画面に282.24usかかります。
●2層目はラインバッファ3つを読む
2層目は図6‐24のように、書いていない3つのバッファを読み出して演算に使います。同図を見ると「1層目が1ライン書く時間」と「2層目が3ライン読む時間」が
同じ
でなければなりません。すなわち2層目は 10.08usで3つのバッファを読み出して出力1ラインを計算します。
●1ラインごと、さらに1画面ごとに同期をとる
またCNN1ブロックが1層目に入る時間は320usなのでその期間も
同じ
にします。したがって2層目もそれに合わせて「休み時間」を設けます。このように各層同期をとってリアルタイム処理を達成します。
次のページへ
目次へ戻る