8‐03 3層目のRAMアクセス(HDL)
●タイムチャートを見ながらHDLを書いてみる
2層目はRAM_X2(4個のラインバッファからなる)に書き、3層目はそれを読みます。
2層目はRAM_X2_WR_SELという信号でラインバッファを0〜3まで順番に書き込みます。ただ、2層目にはプーリングがあるので選択の周期は遅くなり(20.16us)、CnnLineCountを2分周した信号になります(図8-24)。
3層目はRAM_X2_RD_SEL(このタイムチャート)という信号で読み出しバッファを選択しますが、それはCnnLineCountを2分周したものに1を足して、さらにKernelVを足したものです。そうすればこのように書き込みバッファを追いかけることができます(*1)。
また読み出しアドレスRAM_X2_RD_ADDRはKernelHにCnnPixCountDiv4(CnnPixCountを4分周したもの)を加算します。3層目は入力16chを一つの積和演算器が受け持ちます。したがってこのタイムチャートのようにinCh3Selが0〜15までの期間、すなわちCnnPixCountが0〜3までの期間(360ns
x 4 = 1.44us)で1画素計算するからです。
(*1)層が進むごとにレイテンシが発生するので図8‐24では各信号は適宜遅延させてある |
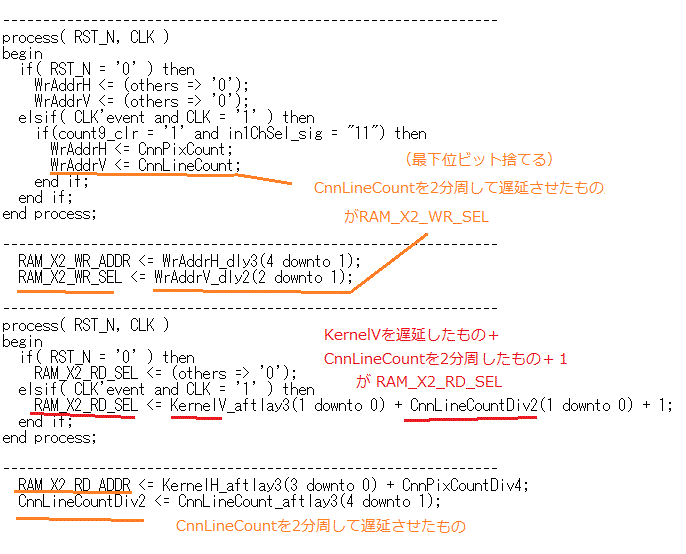
図8-24 RAM_X2の読み出し信号の生成(gts_timing.vhd)
●ラインバッファのアドレスは共通
RAM_X2_RD_ADDRは図8-25のように4つのラインバッファのアドレスとなります。読み出されるデータはRAM_X2_RD_DATA0〜3で、それぞれ5×32=160ビットです(3層目の入力32ch、データ幅5ビットなので)。 |

図8‐25 2層目と3層目の間にある4つのバッファ (gts_hw.vhd)
●4つの読み出しデータをミックスして3層目に入力
RAM_X2_RD_DATA0〜3はRAM_X2_RD_SELで切り替えられてRAM_X2_RD_DATAとなり、conv_layer3(3層目)のLAY3INに入力されます(図8-26)。 |

図8‐26 RAM_X2からconv_layer3へデータ入力 (gts_hw.vhd)
●3層目conv_layer3.vhdの中で入力chが分離される
conv_layer3内部では入力信号の名前はLAY3INとなります。
LAY3INは160ビットですが、そのうち80ビット(bit159〜80)がinch_00になります(*2)。
(*2)図8-27のように、in3ChSelの値により、5ビット×16chが多重化されている。また、RAMの読出しで1サイクル遅延するのに合わせてin3ChSel_dlyとなっている。
同図のようにinch_00には入力ch0〜15が多重化されています。そしてinch_01には入力ch16〜31が多重化されます。一つの積和演算器が入力16ch受け持つことを思い出しましょう。 |

図8‐27 このタイムチャートのin3ChSelで多重化 (conv_layer3.vhd)
●入力が32ch、出力が64ch、積和演算器128個で計算
inch_00とinch_01はそれぞれ別の積和演算器に行きます。図8-28のdotpro_00_00〜dotpro_00_01は出力Ch0を計算します。
3層目の出力は64chあるのでdotpro_01_00〜dotpro_01_01は出力Ch1、dotpro_63_00〜dotpro_63_01は出力Ch63を計算します。 |
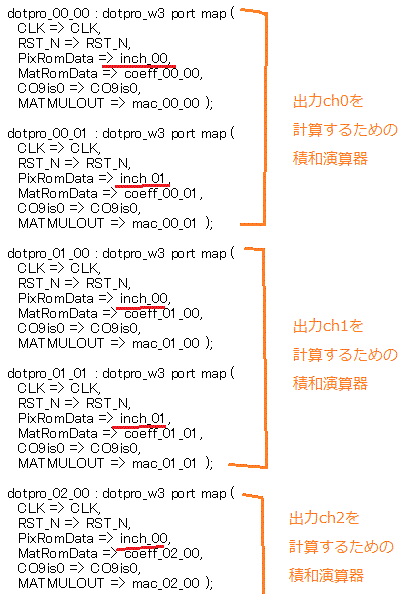
図8‐28 積和演算器dotproは2×64=128個ある (conv_layer3.vhd)
次のページへ
目次へ戻る
|