9‐01 畳み込み4層目は入力64ch、出力128ch
●4層目は乗算器が512個!
図9‐01は4層目の演算イメージです。入力64チャネルを16chづつ4組に分けます(ここ参照)。そしてCh0〜15を1個の積和演算器でまかないます。Ch16〜31、Ch32〜47、Ch48〜63もそれぞれ1個でまかない、計4個の積和演算器で出力1チャネルを計算させます。
出力は128チャネルあるので積和演算器は合計4×128=512個になり、512並列で演算されます。畳み込みの結果、出力画像は一回り小さくなり8×8画素になります(*1)。それがプーリングでさらに小さくなり4×4画素になります。
(*1)入力は11×11なのでカーネルの動く範囲は9×9だが、このように右端下端を捨てる。それからプーリングで間引く |
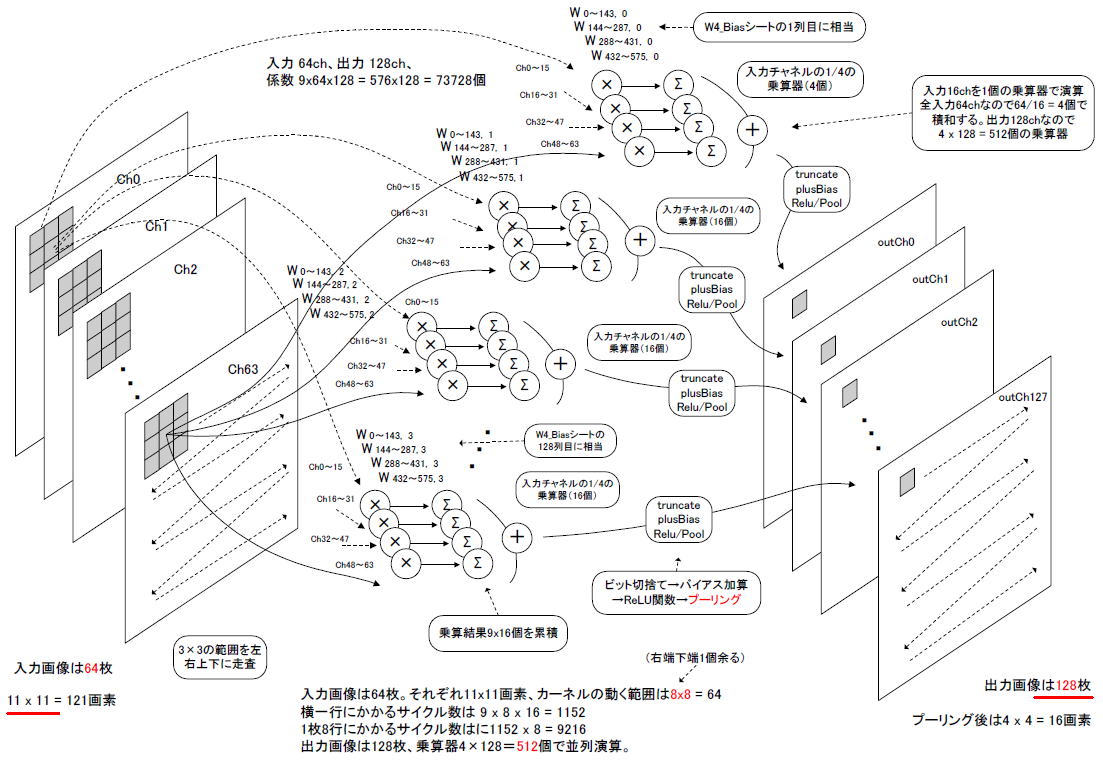
図9-01 4層目は乗算器が512個必要になる → ビットシフトによる乗算、係数は4種類
●乗算器やROMの節約
4層目は乗算器が512個必要になるので、この層も「ビットシフトによる乗算」を行います。また重み係数は4種類(+64, +16, -16, -64)に集約します。これによりROMのビット数を削減することができます。
●1ライン、1画面の演算にかかる時間
入力画像は11×11でカーネル(3x3)の動く範囲は8×8になります(右端下端は捨てる)。したがって横一行にかかるサイクル数は 9 x 8 x 16ch = 1152です(*1)。
(*1)一つの乗算器で入力16chをまかなう。それらは逐次的に処理されるのでx16chのサイクルがかかる
出力1枚は8行なので、かかるサイクル数は 1152 x 8 = 9216、出力は並列で演算されるので、128枚にかかるサイクル数は同じ9216になります。クロック100MHzなら、1行に11.52us、1枚に92.16usかかります(最短で)。 |
●パイプラインなのでスループットに間に合わせる
3層目が1ライン出力するのに20.16usでした。4層目が1ライン出力するのは11.52usなので、パイプライン的に間に合っていることになります。また、ここにあるようにCNNの1ブロックは320usの周期でCNN推論回路に入力されます。上述のように92.16usで処理するので、これも間に合っています(*2)。
(*2)3層目と同期をとるため、4層目は1ライン11.52us + 休み時間 = 20.16us、1ブロック92.16us + 休み時間 = 320usで出力する。 |
●係数ROMは手作業でHDL化するのは大変なので・・・
4層目は入力64ch、出力128chなので係数の数は9×64×128= 73,728個になり、3層目より4倍増えます。これらはROMのデータになりますが、そのHDLファイルはももちろんVBAで自動生成させます。 |
次のページへ
目次へ戻る
|